e' una questione di architettura.
per creare un mondo 3D ci vuole un'architettura capace di risolverti una matrice a 3 dimensioni, tale che puoi fare il cambiamento di base e quindi conoscere come orientare e cuvare le texture.
per risolvere una matrice con 3 vettori devi effettuare 16 passaggi di calcolo, quindi ti ci vuole una pipeline (un processo di computazione) a 16 stadi finiti.
Maxwell l'aveva.
fiji no...
fiji si affidava ad un'architettura superscalare, con tanti core, ma di soli 8 stadi pipeline, e pur avendo 4096 core, risulta piu' lento della 980 TI, che ne conta solo 2880.
attento, qui e' il difficile:
di per se uno stadio lo superi in un clock operativo, quindi 16 stadi = 16 clock = 1 processo completo; 8 stadi = 8 clock = 1/2 processo.... e che ci fai con solo 1/2 processo? nulla...
allora usa altri 4 clock per prendere e metterlo in coda ad un altro (ma anche allo stesso ) core per finire il lavoro... quindi il lavoro diventa 8+4+8=20 clock, o meglio 12+8.
la situazione era questa.
quanto lavoro facevano i due?
2880/16=180
4096/12/2=170.6 (perche' la prima meta' ti costa 12 clock, ma devi fare anche la 2° passata per terminare il lavoro)
a questo punto... quanto lavoro possono fare per la frequenza che hanno?
180*1050mhz=189.000
170.6*1050=179.200
guarda i benchmark:
20507 contro 19315 (rapporto 0.942)
179.200/189.000 (rapporto 0.948)
questo era MAxwell in DX11
ora le DX11 sono alla frutta. non possono piu' tirare la carretta, perche' con al massimo 2 thread, su un multicore da 3 ghz, vai come se avessi un dual core da 3ghz...
la legge di moore e' morta, se consideri solo la frequenza, mentre e' ancora sostenibile se consideri la frequenza per il numero dei core.
il prossimo processore mainstream intel avra' 8 core ma clockera' al massimo a 3.5ghz.
e questo che cambia?
bhe'... Maxwell aveva il piccolo problema che buttava dentro la pipeline e solo alla fine poteva storare il dato... non era interrompibile...
con l'AC aveva i suoi problemi.
fiji invece poteva fare come gli pareva... aveva un registro a stadio, quindi il calcolo si poteva interrompere, storare, e riprendere da dove si era interrotto, ad esignza della situazione... pero' aveva pipeline corte.
quindi che cosa e' successo:
nvidia si ritrova su TSMC, con un PP a 16nm che va' bene per i core A7 e gia' strabbuzza gli occhi con i chip A9 di apple... consente maggior densita', ma non come il 14nm messo appunto da AMD/GF/Samsung, e non con le stesse rese... con i chip grandi non va' tanto bene.
allora, capito l'andazzo, mette una pezza a Maxwell su AC, introducendo uno stadio intermedio alla pipeline per aggiungere il registro... non lo fa' su tutti gli stadi perche' tra' 16 e 14nm ci passa il 30% di superficie a pari densita' normalizzata (ossia, per un miliardo di transistor a 14nm, con lo stesso spazio relativo dagli altri, ti ci vuole il 30% in piu' di superficie)... gli ci vuole troppa roba per farlo, anche perche' e' abbituata a fare solo 3 chip, quelli PRO, e a disabilitare la parte PRO (che continua ad esserci, ma e' silente), e poi disabilitare vari moduli del processore per fare la sua gamma.
quindi, se ci lasci la roba da PRO, se gia' devi essere il 30% piu' grosso, se le rese son pure scarsine... sai che facciamo? visto che di silicio ne usiamo di piu', e che parte di questo sta' "spento" e non scalda piu' di tanto (perche' la roba disabilitata clocka lo stesso, ma non avendo passaggio, scalda poco), noi mettiamo sta' pezza a Maxwell per le DX12 con un solo stadio aggiuntivo (ma perche' non metterlo accanto e lasciarne solo 16? No, che dobbiamo poi rifare lo stadio per intero... invece ne facciamo solo uno che "prendi dato, clona, metti in reg e metti in pipeline", non tocchiamo gli altri, che vanno bene)... poi?.. a si.. poi, visto che siamo un po' piu' larghi.. spariamo la frequenza e recuperiamo le prestazioni...
hei capo, ma e' rischioso!
non abbiamo alternativa, senno' ci tocca proggettare una maschera a chip... e quanto ci costa (e quanto ci stiamo!).
quindi nasce Pascal, che non e' tanto piu' piccolo di Maxwell, adotta nuove e fantastiche tecnologie (aka: misero reg in piu'), tali che in VR ti da' il doppio....
ehm.. signori, no... in VR puo' garantire il doppio solo se diciamo ai programmatori che devono fare in modo che il giocatore non pieghi la testa da un lato, con un occhio piu' alto e uno piu' basso...
e perche' mai?!?
he capo, ci ha fatto mettere solo un reg?
con quello possiamo spostare mezza matrice e rifare l'immagine da un'altra prospettiva, ma solo se il tizio rimane con gli occhi paralleli all'orizzonte, perche' se piega di lato la testa non possiamo semplificare la matrice a sole 2 dimensioni ed una vincolata... ne abbiamo tutte e tre, con tutti e tre i gradi di liberta' che sono necessari... e cosi' non ci facciamo nulla.... il nostro SMP fantastico per il multimonitor, sugli occhialetti 3D deve funzionare allo stesso modo: visuale con un asse vincolato, ossia quello orizzontale.
ok, ma a prestazioni? come siamo messi?
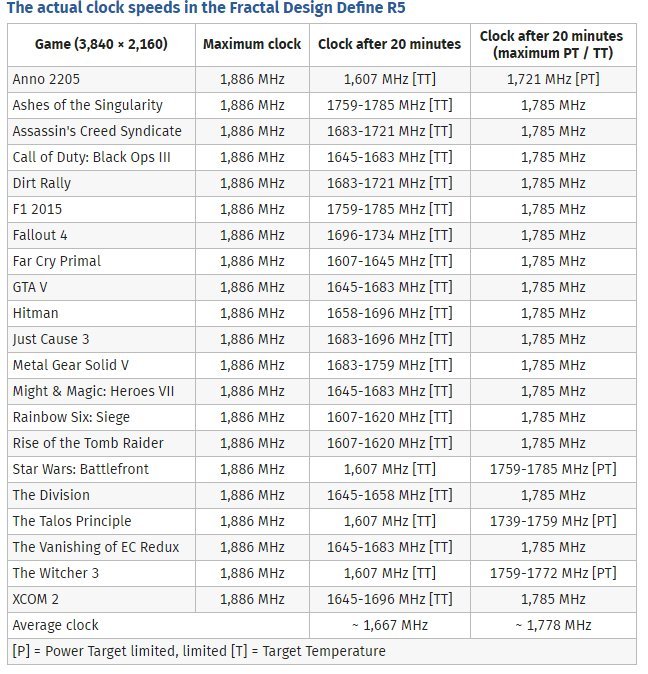
e, bhe'... prima, con 2880 cuda a 1050mhz facevano 189000 work, ora ne abbiamo potuti mettere solo 2560, ma possiamo spingerci a 1866 ad aria per almeno 20 minuti!
solo che ora eseguiamo 16/17 dei work di prima, perche' siamo piu' lunghi di pipeline, percio' siamo a...2560/17*1866=281.000 work!
fantastico, abbiamo migliorato!
e bhe'... per i primi 20 minuti siamo al ( 281.000/189.000=1.48...) 50% superiore a 980Ti! ossia 980Ti vale il 67.3% della nuova scheda!
ma solo per 20 minuti...
come 20?
e si... il die e' piccolo... ci buttiamo dentro 180W (anzi.. le volevo dire... abbiamo deciso di non mettere l'altro 6 pin di alimentazione, perche' senno' tutti a giocare con l'overclock e bruciano un sacco di schede... poi si fanno una brutta fama...)... si, si.. avete fatto bene...
insomma, quanto va'?
tolto l'overclock?
facciamo 241.000 work, il 33.8% in piu' di Ti... una Ti vale il 75% della nostra nuova scheda... Ma solo dopo 20 minuti!
e c'e' un problemino...il bus e' piccolo, e in 4K, anche con le 2.5ghz, non ce la fa' piu' di tanto...
quindi?
quindi in 4k siamo proprio al limite...la ristrettezza di banda ci fa' perdere il vantaggio dell'overclock...
vabe'... rimedieremo con la prossima.. ora fammi fare 2 conticini e fammi preparare un bel discorsetto..
dall'altra parte?
i 14nm?
vanno bene.
le HMB2?
non ce le fanno fino a settembre.
la matrice?
l'abbiamo messa a 16 stadi con reg.
le DDR ci possono andare bene?
mettiamo quelle dell'anno scorso.
e le DDRx?
le usiamo sulle X.
e il VR?
possono pure saltare come pinguini fuori dall'acqua, la matrice regge tutto.
bene...
e i consumi?
stiamo aspettando gli altri... se loro alzano, noi alziamo, se loro abbassano, noi abbassiamo; comunque siamo il 30% in meno... sempre.
bene, bene...
quanto dobbiamo aspettare?
il computex.
eh... ma sono 6 mesi...
faciamo un tresette?
..ma Jim? ha finito il lavoro?
si.
dove sta'?
mha.. e' salito su una macchina, e se ne e' andato.
non e' passato manco a salutarmi!?!?
lui e' cosi'...
tresette?
oggi cazzeggio... scusate.
- - - Updated - - -
fa' 2300mhz a tirargli il collo sotto liquido e a mandargli 260W su 314mm^2...
680: 294mm^2 195w
770: 294mm^2 230W
980: 398mm^2 165W
anche sparata al massimo arrivava a 220-230W
un chip puo' sopportare al massimo 0.75-0.8W mm^2.
314*0.75=235
314*0.80=250
questo e' il range operativo prima di bruciarlo...
180W*2300/1607=258W, e senza alzare il vcore...
logico, qui e' la somma di memoria e chip (e circuiteria), ma quel chip non sale a piu' di 2300 su un normale sampler...(se lo raffreddi a liquido).