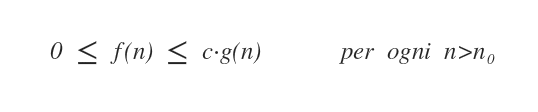L'analisi di complessita' e' detta asintotica se i il numero dei dati tende all'infinito.
La ricerca dicotomica e' una ricerca che opera all'interno di un array ordinato.
Onestamente, parlando di ricerca dicotomica, in un forum di programmazione, mi sono riferito alla compessita' dell'algoritmo in questione, piu' che alla notazione asintotica in matematica e degli algoritmi in generale.
Poi con la mia esemplificazione cercavo di far comprendere, in termini pratici, a cosa facessero riferimento determinati simboli... come poterli associare "praticamente" ad un algoritmo (anzi, a quest'algoritmo in particolare)... anche perche' dal punto di vista teorico ci sono tante documentazioni fatte molto meglio di come potrei scriverela io.
Da dove deriva questa esemplificazione?
Detta T(n) la nostra ricerca dicotomica:
"O" definisce sempre il limite superiore della complessita' dell'algoritmo,... meglio: O(f(n)) definisce questo limite come funzione asintotica, con f(n) funzione maggiorante.
Dal punto di vista di calcolo di un algoritmo generale,
"O" e' la stima per eccesso fatta di quell'algoritmo... (parliamo in termini di tempo)
Nel caso particolare, nella ricerca dicotomica, questo limite superiore e' appunto O(log2(n))... o meglio, dovendo parlare in termini di tempo: assegnato un tempo t=1s ad ogni comparazione (in modo semplicistico), il tempo di esecuzioine diventa log2(n)s, dove n e' il numero degli elementi.
In definitiva il numero di iterazioni (tempo di esecuzione) di T(n) non sara' mai superiore ad O(log2(n)) (dove log2(n) e' funzione maggiorante di T(n)), quindi scrivere O(log2(n)) equivale a dire che il tempo di calcolo dell'algoritmo dicotomico sara' sempre
<= a log2(n)s, o se vuoi, il numero di iterazioni sara' sempre
<= a log2(n).
O ancora scrivere T(n) = O(log2(n)) ... equivale a scrivere T(n) <= log2(n)
O in modo esaustivo e generale dire: "la complessita' di T(n) e' O(f(n))"... e' come dire: "il tempo di esecuzione di T(n) e' <= f(n)"
Da qui l'esemplificazione
O equivale a
<=
Analogo discorso per
OMEGA, che definisce la stima per difetto dell'algoritmo.
Teta definisce un limite asintoittioco stretto... meglio:
Teta(f(n)) definisce strettamente l'andamento dell'algoritmo T(n), con f(n) che cresce come T(n), incanalando T(n) tra due andamenti della funzione f(n): a*f(n) <= T(n) <= b*f(n) (a, b > 0)
Tralasciando tutti i passaggi fatti per "
O", dire che "la complessita' di T(n) e' Teta(f(n))" equivale a dire che "il tempo di esecuzione di T(n) e'
uguale a f(n)"
Passando alla nostra ricerca dicotomica T(n), nel caso in cui non vi siano mai occorrenze, scrivere T(n) = Teta(log2(n)) equivale a scrivere che T(n) == log2(n).
Per cio' che riguarda "
o" e "
omega" definiscono rispettivamente f(n) come funzione
strettamente maggiorante, e funzione
strettamente minorante di T(n).
Da qui l'esemplificazione descritta.
Mi preme aggiungere, per evitare fraintendimenti:
Queste esemplificazioni non devono
mai essere utilizzate per sostutire la simbologia, e' solo un modo "pratico" per comprendere/ricordare un concetto.
P.S.
Il tempo, in un algoritmo, in realta' e' una somma pesata delle singole istruzioni.
In questo esempio, di ricerca dicotomica, ho esemplificato/sostituito il tempo di caclolo con il numero di iterazioni, in quanto il costo di una "comparazione" e' simile nell'andamento dell'algoritmo, cosi', per semplificare tutto, il tempo e' stato associato/sostituito al numero di comparazioni/iterazioni.
il log2(n) e' quindi log2(5)?
Si', ma essendo log2(n) un numero appartenete ad R, mentre il numero di iterazioni e' un numero appartenete a N, il numero di iterazioni dell'algoritmo deve essere approssimato per eccesso.
Per es. log2(5) = 2.3xxxx -> numero di MASSIMO di iterazioni = 3
Forse e' piu' corretto dire che il numero massimo di iterazioni e' floor(log2(n) + 1) ... usando una notazione C