Lo hai compilato o hai compilato qualche esempio?
Hai provato a modificarne qualcuno per vedere cosa succede cambiando i parametri?
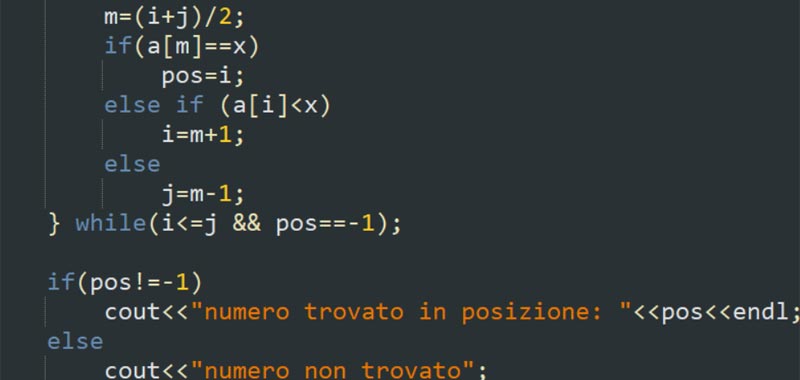
Credo che manchi un po' di buona volonta' nel capire cosa fa il codice, visto che ne avevamo anche parlato in privato e ti avevo indirizzato proprio a questo esempio (che e' anche commentato):
L’algoritmo di ricerca binaria o dicotomica è un algoritmo che viene utilizzato per trovare elementi in un array ordinato. Si usa il termine dicotomica

www.codingcreativo.it
Ti avevo anche indirizzato a quello in C contenuto in Wikipedia, ma
soprattutto ci sono esempi, molto elementari, anche nelle dispense del professore che mi hai fatto vedere... capisco che son 30 pagine, ma lo studio gioverebbe allo scopo.
Oltretutto, come ti avevo anche gia' scritto, ci sono molti altri esempi in rete, anche in italiano (e' un algoritmo molto comune), ma non basta solo andarli a consultare, bisogna passare del tempo a comprenderli.
E bisogna anche imparare il linguaggio di programmazione andandosi a "guardare", per esempio, cosa fa il #define, che e' una
semplicissima direttiva del preprocessore C/C++:
Altre informazioni su: direttiva #define (C/C++)
docs.microsoft.com
che qui ti chiarisco in modo semplicistico, in questo caso:
#define N 5
associa ad N il numero 5, ossia dove c'e' N e' come se ci fosse 5
in questo caso (e solo in questo caso, non e' da generalizzare!) e' come se scrivessi:
const int N = 5;
Se poi hai dei dubbi su qualche passaggio particolare (e non su tutto il codice, perche' altrimenti sembra che tu non l'abbia nemmeno guardato), saro'/saremo lieti di aiutarti.