xxskorpion88xx
Nuovo Utente
- Messaggi
- 9
- Reazioni
- 0
- Punteggio
- 24
Salve a tutti ragazzi, mi presento sono Mario e mi sono iscritto perchè sono convinto che voi meglio di me potete chiarire i dubbi che mi attanagliano (dopo ore e ore di calcoli, ho deciso che mi serviva l'aiuto di esperti xP)
Brevemente vi illustro il nodo del problema:
Analizziamo le varie interfacce di collegamento tra northbridge e CpU con le relative bandwith sul mercato:
Partendo da intel, abbiamo QPI che nella sua ultima versione raggiunge la velocità di 25.6 GB/s
(il calcolo è raggiunto considerando il modo in cui è fatto il processore è visibile qua
Analizzando il versante AMD che usa HyperTransport 3.1 abbiamo un massima banda passante di: 51.2 GB/s
..il calcolo è visibile qua
Riassumendo: una breve tabella con i valori di badwidth è presente su wikipedia inglese e riassume brevemente il tutto.
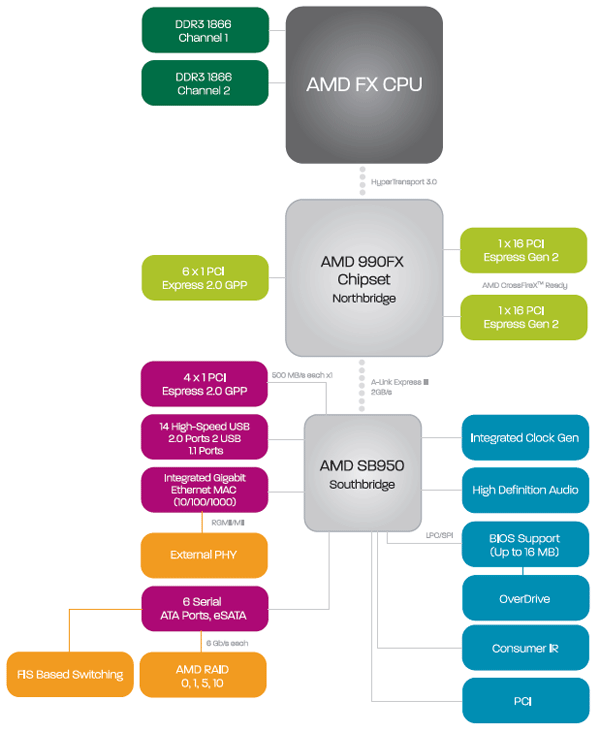
Perfetto: una volta stabilita l'ampiezza del canale di comunicazione che dovrebbe essere quello a maggior bandwith di tutto il sistema per evitare colli di bottiglia tra northbringe e cpu che strozzerebbero il processore e di conseguenza tutto il sistema (vedi foto in basso magari una foto emprime meglio in concetto)

Una volta stabilita l'ampiezza massima dei 2 canali passiamo al calcolo del "traffico" passante in questi, usando come riferimento 2 cpu che vanno molto di moda in questo momento: la 2700k e FX-8150.
Per la intel 2700k abbiamo:
Prendendo per buono per questo screen, calcoliamo il FSB a quelle frequenze che sarebbe:
99.8 Mhz (velocita bus) * 16 moltiplicatore * 8 Byte (64 bit [ampiezza del bus]) * 4 (numero di istruzioni per ciclo) = 49,9 GB/s (
ove l'interfaccia di comunicazione supporta massimo 25.6 GB/s )
per il come è stato condotto il calcolo rimando a FSB su wikipedia
Analizziamo ora la FX-8150 :
Calcolando abbiamo:
200,7(bus speed) * 18(moltiplicatore) * 8 Byte * 4 istruzioni/s = 112,5 GB/s (ove l'interfaccia supporta massimo 51.2 GB/s )
Chiedo il supporto di un esperto per capire se effettivamente è questo lo scenario attuale.
Se effettivamente è cosi, le conclusioni a cui sono arrivato io sono molteplici:
1)ci vendono BESTIE di processori che sono CAPPATI dall' interfaccia:
2)Ad occhi chiusi prenderei un BUlldozer (altro che buldozer fallimento) sfruttate tutti i 51GB/s a pieno (pur perdendone altri 60 abbondanti dato il bottleneck del HyperTransport 3.1
Edit: tra l'altro mi sono accorto che la 2700k non utlizza il QPI come si può vedere qua ma utilizza la semplic einterfaccia DMI 2.0 con un BUS udite udite di appena 2 GB/s ... Che vergogna :(
Dite la vostra e chiaritemi le idee!! grazie :P
Brevemente vi illustro il nodo del problema:
Analizziamo le varie interfacce di collegamento tra northbridge e CpU con le relative bandwith sul mercato:
Partendo da intel, abbiamo QPI che nella sua ultima versione raggiunge la velocità di 25.6 GB/s
(il calcolo è raggiunto considerando il modo in cui è fatto il processore è visibile qua
The rate is computed as follows:3.2 GHz (velocità del trasferimento qpi ultima versione)× 2 bits/Hz (double data rate)× 20 (QPI link width)× (64/80) (data bits/flit bits)× 2 (unidirectional send and receive operating simultaneously)÷ 8 (bits/byte)= 25.6 GB/s
Analizzando il versante AMD che usa HyperTransport 3.1 abbiamo un massima banda passante di: 51.2 GB/s
..il calcolo è visibile qua
HyperTransport supports an auto-negotiated bit width, ranging from 2 to 32-bit per link; there are two unidirectional links per HT bus. With HT version 3.1, using full 32-bit links and utilizing the full 3.1 specification's operating frequency, the theoretical transfer rate is 25.6
Perfetto: una volta stabilita l'ampiezza del canale di comunicazione che dovrebbe essere quello a maggior bandwith di tutto il sistema per evitare colli di bottiglia tra northbringe e cpu che strozzerebbero il processore e di conseguenza tutto il sistema (vedi foto in basso magari una foto emprime meglio in concetto)
Una volta stabilita l'ampiezza massima dei 2 canali passiamo al calcolo del "traffico" passante in questi, usando come riferimento 2 cpu che vanno molto di moda in questo momento: la 2700k e FX-8150.
Per la intel 2700k abbiamo:
Prendendo per buono per questo screen, calcoliamo il FSB a quelle frequenze che sarebbe:
99.8 Mhz (velocita bus) * 16 moltiplicatore * 8 Byte (64 bit [ampiezza del bus]) * 4 (numero di istruzioni per ciclo) = 49,9 GB/s (
ove l'interfaccia di comunicazione supporta massimo 25.6 GB/s )
per il come è stato condotto il calcolo rimando a FSB su wikipedia
Analizziamo ora la FX-8150 :
Calcolando abbiamo:
200,7(bus speed) * 18(moltiplicatore) * 8 Byte * 4 istruzioni/s = 112,5 GB/s (ove l'interfaccia supporta massimo 51.2 GB/s )
Chiedo il supporto di un esperto per capire se effettivamente è questo lo scenario attuale.
Se effettivamente è cosi, le conclusioni a cui sono arrivato io sono molteplici:
1)ci vendono BESTIE di processori che sono CAPPATI dall' interfaccia:
2)Ad occhi chiusi prenderei un BUlldozer (altro che buldozer fallimento) sfruttate tutti i 51GB/s a pieno (pur perdendone altri 60 abbondanti dato il bottleneck del HyperTransport 3.1
Edit: tra l'altro mi sono accorto che la 2700k non utlizza il QPI come si può vedere qua ma utilizza la semplic einterfaccia DMI 2.0 con un BUS udite udite di appena 2 GB/s ... Che vergogna :(
Dite la vostra e chiaritemi le idee!! grazie :P