filoippo97
Utente Èlite
- Messaggi
- 14,077
- Reazioni
- 7,630
- Punteggio
- 217
“24 bit sono più meglio, lo ha detto mio cugggino che ha lo studio di registrazione nel garage!” “192kHz suona meglio di 44.1kHz perché il numero è più alto!!” “il DSD mi permette di ascoltare anche lo scatarricchio del trombettista nella decima fila di un’orchestra durante un pieno orchestrale, prima non lo sentivo OMG!” quante volte abbiamo sentito queste frasi, dai diciamocelo. Tra chi ne è convinto, anche nel mondo audiofilo, e chi invece ci arriva semplicemente ad intuito perché lo ha letto da altre parti o se lo è immaginato, la questione della ossessiva ricerca del formato a più alta risoluzione ormai ha preso tutti: adulti, vecchi, piccini, cani. Con questo piccolo articolo vorrei fare un attimo più di luce e portare una conoscenza di base su cosa siano realmente quei numeri buttati li, che ormai traggono in inganno moltissimi. Prima iniziamo dalle basi, ovvero di cosa stiamo parlando?
PREAMBOLO
Innanzi tutto ci servono due basi matematiche e concettuali, perché senza non si va da nessuna parte e non si riesce a capire una mazza.
Definiamo cos’è un segnale: un segnale è una qualunque grandezza fisica variabile a cui sia associata un’informazione di interesse, rappresentabile con una funzione matematica. Quanti tipi di segnali esistono? Essenzialmente sono 4 e possono essere cosí suddivisi:

Come possiamo rappresentare tali segnali su carta o al pc? In due modi, nel tempo o in frequenza. Il segnale nel tempo ha sull’asse orizzontale i secondi e mostra sul grafico come varia tale segnale in ampiezza. Da un segnale nel tempo possiamo ricavare la frequenza dello strumento che sta suonando osservando quanto sono vicine le creste della sinusoide, se la nota è grave saranno molto distanti (dal momento che 20Hz per esempio sono 20 ripetizioni della sinusoide al secondo) se la nota è acuta saranno molto veloci (20kHz sono 20 mila ripetizioni della sinusoide in un secondo). Il metodo di rappresentazione per frequenza invece congela un certo istante come se fosse un fotogramma di un filmato e ne mostra tutte le componenti frequenziali presenti, ad esempio se suona un basso e un cimbalo, vedremo una certa presenza nel grafico basso e in quello alto. Come si passa da uno all’altro? Con la Trasformata di Fourier, nei computer FFT (fast fourier transform). Mi limito a saltare la parte più matematica (da corso di analisi III) della trasformata, fornendo quelle notevoli principali.
Come possiamo rappresentare tali segnali su carta o al pc? In due modi, nel tempo o in frequenza. Il segnale nel tempo ha sull’asse orizzontale i secondi e mostra sul grafico come varia tale segnale in ampiezza. Da un segnale nel tempo possiamo ricavare la frequenza dello strumento che sta suonando osservando quanto sono vicine le creste della sinusoide, se la nota è grave saranno molto distanti (dal momento che 20Hz per esempio sono 20 ripetizioni della sinusoide al secondo) se la nota è acuta saranno molto veloci (20kHz sono 20 mila ripetizioni della sinusoide in un secondo). Il metodo di rappresentazione per frequenza invece congela un certo istante come se fosse un fotogramma di un filmato e ne mostra tutte le componenti frequenziali presenti, ad esempio se suona un basso e un cimbalo, vedremo una certa presenza nel grafico basso e in quello alto. Come si passa da uno all’altro? Con la Trasformata di Fourier, nei computer FFT (fast fourier transform). Mi limito a saltare la parte più matematica (da corso di analisi III) della trasformata, fornendo quelle notevoli principali.
Impulso unitario: come dice il nome, è un colpo, un qualcosa di istantaneo, di infinitesimamente piccolo nel tempo e alto 1. La sua trasformata vale 1, ovvero è una retta che copre tutte le frequenze. Ebbene si, in un impulso c’è qualsiasi frequenza immaginabile. La proprietá principale è quella del prodotto: prendete un segnale e moltiplicatelo per un impulso, otterrete lo stesso identico segnale spostato nell’istante di applicazione dell’impulso. Viene anche chiamato detto delta di dirac.

Seno e coseno: i due segnali principali della musica, con i quali poi per somma si fanno tutti i timbri possibili. La trasformata di sin2πft è:

 ovvero due impulsi (uno dei due "immaginario"), dove j é lo sfasamento dato dal seno. Potete provare tranquillamente quel che sto dicendo scaricando da un generatore di toni una sinusoide e vedendola attraverso uno spettrogramma, foobar per esempio ne fornisce uno. Vedrete un solo picco, che è normale dal momento che un seno ad una frequenza x rappresenta una sola frequenza, la x. é un impulso in frequenza se lo vogliamo chiamare cosí.
ovvero due impulsi (uno dei due "immaginario"), dove j é lo sfasamento dato dal seno. Potete provare tranquillamente quel che sto dicendo scaricando da un generatore di toni una sinusoide e vedendola attraverso uno spettrogramma, foobar per esempio ne fornisce uno. Vedrete un solo picco, che è normale dal momento che un seno ad una frequenza x rappresenta una sola frequenza, la x. é un impulso in frequenza se lo vogliamo chiamare cosí.
Rettangolo: una finestra, un valore che parte da zero, va al massimo e torna a zero. La sua trasformata è

(nota: il simbolo pi greco é il modo matematico di indicare la funzione rettangolo, la variabile T é la durata nel tempo per cui 4π(3t) vuol dire un rettangolo che dura 0.33 secondi centrato nell'origine, alto 4 (per esempio 4 volt se é un segnale elettrico)).
notate come sta roba sia in frequenza molto simile ad un impulso, un po' distorto e reso in un certo senso reale

CAMPIONAMENTO
Il suono è come ben sapete un segnale analogico, il segnale in tensione e corrente che esce da un microfono è infatti omogeneo, non presenta scalettature, e segue il normale timbro della voce e di ció che sta captando di altro in quel momento. Dal momento che sugli hard disk il concetto di infinito non esiste, ma al contrario esistono delle dimensioni ben precise, sorge spontanea la domanda: come registro un qualcosa di analogico su un hard disk senza perdere informazioni? Con il campionamento digitale PCM. Molti di voi avranno giá sentito parlare della PCM (da non confondersi con la PWM che non c’entra niente), la PCM è una tecnica che permette la conversione da analogico a digitale e viceversa e sta per Pulse Code Modulation. Immaginiamo ora che dobbiamo registrare una sinusoide ad 1kHz: il processo si svolge in diverse fasi:
la prima fase consiste nel rendere discreto il segnale nel tempo, ovvero di prendere dei punti ad intervalli costanti sulla nostra linea continua in modo da poterli memorizzare. Non possiamo infatti memorizzare gli infiniti punti di un segnale analogico, come detto prima, quindi passeremo prima per un segnale campionato. Viene ottenuto moltiplicando il segnale originario per un treno di impulsi. Gli impulsi avranno quindi altezza pari al nostro segnale (assumeranno il valore del segnale) e nel resto del tempo il segnale sará pari a zero.
 Ovviamente gli impulsi essendo a loro volta di durata infinitesima sono una pura astrazione matematica, peró ci aiutano a capire una prima cosa: avevamo detto che la proprietá di un impulso è quella di spostare in frequenza il segnale, di conseguenza un treno di impulsi ricopierá a distanza pari alla frequenza di campionamento lo spettro del segnale per tutte le volte in cui è presente un impulso.
Ovviamente gli impulsi essendo a loro volta di durata infinitesima sono una pura astrazione matematica, peró ci aiutano a capire una prima cosa: avevamo detto che la proprietá di un impulso è quella di spostare in frequenza il segnale, di conseguenza un treno di impulsi ricopierá a distanza pari alla frequenza di campionamento lo spettro del segnale per tutte le volte in cui è presente un impulso.
 Abbiamo quindi il primo problema, ovvero ci troviamo delle frequenze esattamente uguali a quelle che vogliamo campionare in punti dove non vorremmo ci fosse nulla, ed è qui che entra in gioco il primo criterio di Nyquist: affinché non ci siano sovrapposizioni tra gli spettri del segnale in modo da poter isolare nuovamente il nostro spettro di interesse, vogliamo che tale spettro sia limitato in frequenza (se fosse illimitato si sovrapporrebbe) pertanto la frequenza di campionamento deve essere pari ad ALMENO due volte la frequenza massima.
Abbiamo quindi il primo problema, ovvero ci troviamo delle frequenze esattamente uguali a quelle che vogliamo campionare in punti dove non vorremmo ci fosse nulla, ed è qui che entra in gioco il primo criterio di Nyquist: affinché non ci siano sovrapposizioni tra gli spettri del segnale in modo da poter isolare nuovamente il nostro spettro di interesse, vogliamo che tale spettro sia limitato in frequenza (se fosse illimitato si sovrapporrebbe) pertanto la frequenza di campionamento deve essere pari ad ALMENO due volte la frequenza massima.
 Ed è cosí che si scopre che in segnali ad esempio campionati a 44.1kHz, la frequenza massima registrabile teoricamente è 22.05kHz, mentre in quelli da 192kHz la frequenza massima è 96kHz. Osserviamo come per tagliare di netto esattamente a 22.05kHz e prevenire in questo modo quello che è il fenomeno dell’aliasing (ovvero quando in una riproduzione si sente sia lo spettro in banda base che le sue repliche traslate in banda a frequenza fc) serva un filtro passa basso con pendenza infinita peró, cosa non fisicamente realizzabile. Il motivo per cui si campiona quindi a frequenze elevate quindi, è quello di poter limitare molto prima la frequenza massima in modo da poter usare dei filtri passa basso molto più dolci ed arrivare a 96kHz (nel caso del campionamento a 192kHz) con una pendenza molto lieve del filtro, nei file a 192kHz quindi la frequenza massima in genere gira intorno ai 30kHz. Un filtro di questo tipo infatti presenta rotazioni di fase molto contenute ed è molto più lineare su tutta la banda di nostro interesse. Primo mito sfatato!
Ed è cosí che si scopre che in segnali ad esempio campionati a 44.1kHz, la frequenza massima registrabile teoricamente è 22.05kHz, mentre in quelli da 192kHz la frequenza massima è 96kHz. Osserviamo come per tagliare di netto esattamente a 22.05kHz e prevenire in questo modo quello che è il fenomeno dell’aliasing (ovvero quando in una riproduzione si sente sia lo spettro in banda base che le sue repliche traslate in banda a frequenza fc) serva un filtro passa basso con pendenza infinita peró, cosa non fisicamente realizzabile. Il motivo per cui si campiona quindi a frequenze elevate quindi, è quello di poter limitare molto prima la frequenza massima in modo da poter usare dei filtri passa basso molto più dolci ed arrivare a 96kHz (nel caso del campionamento a 192kHz) con una pendenza molto lieve del filtro, nei file a 192kHz quindi la frequenza massima in genere gira intorno ai 30kHz. Un filtro di questo tipo infatti presenta rotazioni di fase molto contenute ed è molto più lineare su tutta la banda di nostro interesse. Primo mito sfatato!
Secondo mito da sfatare: “ma i 192kHz rappresentano meglio la banda audio perché la risoluzione è più elevata!” sbagliato: un 44.1kHz rappresenta una frequenza 20kHz esattamente come un 192kHz. Avete mai fatto quei giochi di unire i punti in modo da generare una figura? Mi sapreste disegnare una sinusoide attraverso questi tre punti? E attraverso questi 6?
 Come potete vedere provando su un foglio di carta, non cambia nulla, l’unica cosa che cambia è che nella seconda figura potete rappresentare senza equivoci anche la sinusoide a frequenza doppia. Nel primo caso se provate a fare la sinusoide a frequenza doppia date origine all’aliasing, che infatti non è altro che l’impossibilitá del DAC di determinare se i punti rappresentano la sinusoide a frequenza X o a frequenza 2X (ecco perché si originano delle repliche dello spettro, che noi possiamo comunque tagliar via conoscendo la frequenza di campionamento). L’UNICO VERO MOTIVO per cui si campiona a frequenze più elevate è quindi quello di poter usare filtri passa basso più lenti, in modo che siano più lineari (si potrebbe dimostrare, ma richiede conoscenze anche di teoria dei circuiti e di elettronica) e quindi meno impattanti sulla banda audio. Attualmente specialmente nei prodotti hifi, i filtri LPF antialiasing dei DAC sono estremamente lineari anche a 44.1kHz, rendendo tutte le frequenze di campionamento superiori a questa o al limite superiori a 96kHz una simpatica trovata di marketing. La parte di spazio che viene lasciata per permettere ai filtri di operare viene chiamata banda di guardia, per un 44.1kHz di norma la frequenza massima registrata è intorno ai 20.5kHz, permettendo una banda di guardia di circa 1.5kHz, per un 192kHz di solito si registra massimo fino a 30kHz permettendo una banda di guardia di un notevole 162kHz.
Come potete vedere provando su un foglio di carta, non cambia nulla, l’unica cosa che cambia è che nella seconda figura potete rappresentare senza equivoci anche la sinusoide a frequenza doppia. Nel primo caso se provate a fare la sinusoide a frequenza doppia date origine all’aliasing, che infatti non è altro che l’impossibilitá del DAC di determinare se i punti rappresentano la sinusoide a frequenza X o a frequenza 2X (ecco perché si originano delle repliche dello spettro, che noi possiamo comunque tagliar via conoscendo la frequenza di campionamento). L’UNICO VERO MOTIVO per cui si campiona a frequenze più elevate è quindi quello di poter usare filtri passa basso più lenti, in modo che siano più lineari (si potrebbe dimostrare, ma richiede conoscenze anche di teoria dei circuiti e di elettronica) e quindi meno impattanti sulla banda audio. Attualmente specialmente nei prodotti hifi, i filtri LPF antialiasing dei DAC sono estremamente lineari anche a 44.1kHz, rendendo tutte le frequenze di campionamento superiori a questa o al limite superiori a 96kHz una simpatica trovata di marketing. La parte di spazio che viene lasciata per permettere ai filtri di operare viene chiamata banda di guardia, per un 44.1kHz di norma la frequenza massima registrata è intorno ai 20.5kHz, permettendo una banda di guardia di circa 1.5kHz, per un 192kHz di solito si registra massimo fino a 30kHz permettendo una banda di guardia di un notevole 162kHz.
Siccome il campionamento mediante delta di dirac non è praticabile nella realtá, si utilizzano in realtá dei piccolissimi rettangoli, tale metodo viene chiamato sample and hold (il delta-sigma usato in realtá è ancora un’altra cosa).

Ricordate come i rettangoli in frequenza abbiano un comportamento che ricorda un impulso distorto? É una approssimazione reale del campionamento ideale.
L’altro passaggio è quello di limitare in ampiezza il segnale, ovvero tra gli infiniti valori di tensione che può assumere, stabilirne un determinato numero ed assegnare solo quelli.

Tale procedimento prende il nome di quantizzazione e i valori vengono chiamati livelli di quantizzazione. Ad ogni campione viene associato quindi un livello di quantizzazione espresso in bit, dove 16 bit sono quindi 2^16=65536 livelli e 2^24 sono 16777216 possibili valori. Ovviamente ci sará un errore detto di quantizzazione dato dal fatto che l’ADC non sa se scegliere il valore sopra o quello sotto. L’errore è dato dalla differenza tra il valore massimo e quello minimo possibili (la dinamica del segnale, quindi se il nostro segnale varia tra 0 e 2V sará 2) diviso 2Q, dove Q è il numero di livelli, e il 2 davanti è dovuto al fatto che si fa l’approssimazione per difetto o per eccesso. Più sará grande Q, è minore sará la scalettatura del segnale.
Alla fine abbiamo quindi ottenuto il nostro segnale digitale pronto per essere memorizzato in un file .wav. Terzo mito da sfatare: “più bit abbiamo, migliore sará il suono perché il segnale ha meno errore quindi!” sbagliato: o meglio in teoria avreste ragione, ma la teoria è diversa dalla pratica, infatti i segnali in uscita dai DAC hanno una tensione tipicamente molto bassa per evitare di friggere tutto quello che sta a valle, ricordiamoci che non sono dispositivi di potenza come degli amplificatori. Tale dinamica molto bassa (2V, 4V per i segnali bilanciati – che approfondiremo più avanti) rende giá l’errore di un 16 bit assolutamente microscopico (stiamo parlando quindi di 15 nanovolt) su un 24 bit tale errore è talmente insignificante che viene ampiamente superato dai rumori sulle linee di alimentazione (ecco perché sono importanti sui dac) e dalle precisioni dei resistori nel caso di dac a scala di resistenze. Per farvi un esempio, per stessa ammissione dell’azienda, lo Schiit Yggdrasil, un dac top di gamma da 2600 euro utilizzante quattro dac in cascata di livello militare da 200 euro al chip (dove un delta sigma tradizionale di livello elevato costa 5-6 euro) arriva a 21 bit reali. Un dac da 100 euro ho francamente dei dubbi riesca ad arrivare anche solo a 17 bit reali, tutto il resto è pura fuffa.
Ricapitolando quindi:
limitazione del segnale da codificare al massimo a fc/2 -> campionamento -> quantizzazione -> digitalizzazione.
Il flac è senza dubbio il formato maggiormente conosciuto, esso è come un wav zippato: una volta decompresso on the fly in riproduzione otterrete lo stesso wav con la stessa qualitá dell’originale. Il wav non è superiore al flac, semplicemente il flac è come un archivio rar specializzato per contenere musica, ma il contenuto non viene toccato, infatti è compresso senza perdita.
L’MQA è un formato compresso con perdita di invenzione di Meridian Audio. Anziché offrire una quantizzazione lineare (ovvero con un errore sempre costante) attraverso tecniche di convoluzione e dithering si ottiene un formato con una quantizzazione non lineare, ovvero con un errore sempre crescente mano a mano che si sale in frequenza. Tale logica è suffragata dall’idea che le alte frequenze portano molta meno energia di quelle basse, e quindi un errore in alta frequenza è molto meno percepibile rispetto ad uno in bassa frequenza. Il risultato viene poi compresso con perdita nel formato proprietario, portando le alte frequenze a frapporsi alle basse (mediante dither appunto, come se piegassimo un foglio di carta su sé stesso). I dispositivi che supportano l’MQA via hardware permettono di decodificare il dither applicato e di ottenere nuovamente lo spettro completo, quelli che non lo supportano necessitano di farlo via software e di convertire prima il segnale in PCM.

Il DSD lavora invece su tutt’altra tecnica, la PCM qui non c’entra più una mazza. Il DSD sfrutta la PWM, pulse width modulation: immaginate di poter esprimere una frequenza mediante la modulazione della larghezza di un’onda quadra, che assume quindi solo due valori (ecco perché si dice DSD 1 bit). Avendo un solo bit qui ad aumentare sará la frequenza, fino ai livelli del MHz noti (2.8MHz, 5.6MHz, 11.2MHz) eliminando quindi tutti gli errori dovuti alla quantizzazione, o almeno questa è l’idea. In codifica viene semplicemente fatto passare il segnale in un modulatore PWM, che è fatto con una sorta di comparatore che sceglie se attribuire 0 o 1 in base a dove si trova il segnale. In decodifica e riproduzione, il segnale originato, l’onda quadra, passa in un filtro passa basso che taglia via a frequenze molto inferiori alla portante, per esempio 2.8MHz viene tagliato intorno ai 22kHz. Tale taglio non permette ovviamente di far passare l’onda quadra per intero ma una sua approssimazione “smussata”, la sinusoide di partenza. Di preciso, si nota che tagliando via a frequenze più basse il valore assunto dal segnale corrisponde all’area del rettangolo dell’onda, per cui un’onda quadra molto stretta genera un segnale vicino allo 0 mentre un’onda quadra molto larga un segnale vicino al massimo (2V tipicamente), per approssimazione. È abbastanza intuitivo. È LO STESSO IDENTICO sistema di funzionamento di un alimentatore switching come quelli per PC, solo che li la frequenza è fissa e tarata per generare una tensione di 12V. Facendo variare la frequenza come nel DSD si produce un amplificatore in classe D, anch’esso lavora sul principio della PWM, dove i transistor sono solo utilizzati in commutazione (0 e 1) e mai in zona lineare.
 nella figura abbiamo rappresentati il segnale in ingresso (input), il segnale di riferimento che genera la "cadenza" dell'onda quadra con il nome di reference signal, e l'output quadro. Notate come l'output assume larghezze differenti simili all'andamento dell'input.
nella figura abbiamo rappresentati il segnale in ingresso (input), il segnale di riferimento che genera la "cadenza" dell'onda quadra con il nome di reference signal, e l'output quadro. Notate come l'output assume larghezze differenti simili all'andamento dell'input.
Quali sono i vantaggi reali? Beh come funziona la modulazione delta-sigma? Intanto cosa significa delta-sigma? Delta rappresenta un impulso (la delta di dirac per l'appunto), sigma significa somma di impulsi (il simbolo della sommatoria matematica). Notate somiglianze? Eh giá sono la stessa cosa (quasi - in realtá é leggermente diversa ma comunque simile come concetto): delta-sigma e modulazione a larghezza di impulsi (pulse width modulation) sono quasi la stessa cosa, infatti i dac e gli adc nativamente funzionano proprio in questo modo, quindi per registrare in DSD basta prendere l'out grezzo dell'adc e senza passaggi in codificatori PCM ma solo con poche manipolazioni, inciderlo su disco, il SACD. Per lavorare in PCM infatti un dac o un adc ha bisogno di passaggi intermedi che permettono la decodifica in delta sigma mediante un lavoro in parallelo non molto distante da una sorta di multithreading (qualcuno ricorda il multibit di schiit... quello lavora nativamente in PCM, guarda caso non accetta stream DSD... guarda caso sui vecchi prodotti audio, ho giusto qui sotto mano un lettore cd kenwood dell'anteguerra, quando la tecnologia era agli albori si chiamavano dac 1 bit e non ancora delta sigma...). Il DSD é quindi meglio del PCM? Ni, o meglio, sebbene elimini gli errori dati dalla quantizzazione, il campionamento viene condotto ad altissima frequenza e giá questo puó introdurre errori che lo rendono piú sensibile al jitter (problemi derivanti dalla sincronizzazione con i clock) in piú il comparatore introduce errori dovuti al fatto che puó scegliere tra soli due valori e tale errore consiste solo in uno spostamento di responsabilitá rispetto ai classici errori di quantizzazione per la PCM.
L'MP3 é nato intorno agli anni '90 e si proponeva di ridurre il grande volume di dati occupato da un file wav PCM in livelli molto piú accettabili per dei dispositivi portatili. siccome giá 44.1kHz era la frequenza minima imposta per campionare senza perdere dati nella banda audio, si é inizialmente scelto di diminuire i campioni a 8 bit, dimezzando la mole di dati (44.1kHz x 16 bit x 2 originava un flusso da 1411kbit/s, con 8 bit si passava a 705.5kbit/s) ottenendo peró un suono parecchio peggiore, a livelli veramente pessimi. Si é quindi pensato di passare a considerare il segnale in frequenza, lo spettro. Dividendo tale segnale in 32 sottobande con dei filtri e campionando tale spettro come se fosse un segnale nel tempo si possono utilizzare largamente meno bit, permettendo una occupazione notevolmente minore. Accanto all'MP3 si sviluppava anche tutta una ricerca su modelli percettivi del suono, per fare in modo di tagliar via le frequenze poco importanti (esempio oltre i 18kHz e sotto i 20Hz) in modo da rendere piú fitte le 32 bande e concentrare la precisione nelle frequenze di maggior interesse, codificati con codificatori come LAME, si ottengono i risultati che oggi conosciamo con bitrate massimi di 320kbit/s. Ulteriori miglioramenti in termini di compressione sono stati introdotti con il codec MP3 joint stereo, dove si osservava che i segnali destro e sinistro presentano essenzialmente poche variazioni l'uno con l'altro, per cui si registrava in mono e su una traccia a parte si registravano le sole variazioni da un canale all'altro, migliorando sensibilmente l'occupazione in termini di dati utilizzati. É stato introdotto non molto tempo fa il formato VBR, ovvero variable bit rate, che prevede l'associazione a ciascuno dei 32 frame di spettro (chiamati chunks) di un numero di bit differenti a seconda sia della dinamica del segnale, sia considerando il fatto che la gamma bassa essendo meno complessa necessita di meno bit rispetto a quella alta, in una maniera analoga alla quantizzazione non lineare.
LA STREGONERIA DEI SEGNALI BILANCIATI
Visto che su internet ormai si legge di tutto, non é raro leggere anche di gente che preferisce la connessione bilanciata perché "é piú meglio" - credo ci sia anche una setta del segnale bilanciato, come esistono quelle per i cavi di alimentazione in tondini d'argento, probabilmente l'inizializzazione é un qualcosa di strano dove gente viene legata tramite cavi XLR e poi succedono cose che non ci é dato sapere. Per capire come questa storia del bilanciato come segnale preferibile sia una bufala, bisogna capire prima come funziona un segnale bilanciato e qual é la differenza con uno sbilanciato. Nel segnale sbilanciato, abbiamo un riferimento a 0V che viene mantenuto costante ed é il negativo, la parte esterna di un RCA, mentre il vero segnale viaggia tutto sul positivo, il pin centrale. Questo sistema rende la trasmissione vulnerabile ad eventuali rumori, vedi figura.
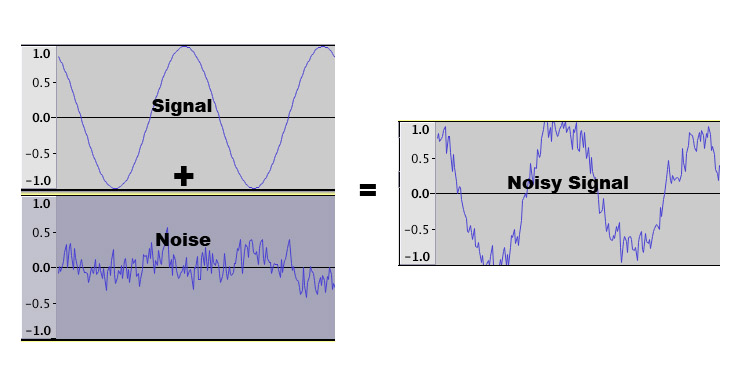 Il segnale bilanciato invece fa affidamento su tre conduttori: uno chiamato GND che tiene fisso il riferimento a 0V, uno chiamato HOT che trasporta il segnale originale e uno chiamato COLD che lo trasporta a polaritá inversa (quindi se HOT é a 2V, COLD sará a -2V), ottenendo un effetto esattamente specchiato. Durante il percorso nel cavo ovviamente tale segnale puó incappare in rumori elettronici ed interferenze che ovviamente colpiscono sia il polo HOT che il COLD alla stessa maniera, ma una volta a destinazione il polo COLD viene ribaltato nuovamente ottenendo un segnale identico all'HOT, a cui viene sommato. Il risultato sará che il segnale raddoppia in tensione (ecco perché sugli XLR gira tensione doppia rispetto agli RCA, giá questo irrobustisce la resistenza al rumore) mentre il rumore si somma in controfase annullandosi.
Il segnale bilanciato invece fa affidamento su tre conduttori: uno chiamato GND che tiene fisso il riferimento a 0V, uno chiamato HOT che trasporta il segnale originale e uno chiamato COLD che lo trasporta a polaritá inversa (quindi se HOT é a 2V, COLD sará a -2V), ottenendo un effetto esattamente specchiato. Durante il percorso nel cavo ovviamente tale segnale puó incappare in rumori elettronici ed interferenze che ovviamente colpiscono sia il polo HOT che il COLD alla stessa maniera, ma una volta a destinazione il polo COLD viene ribaltato nuovamente ottenendo un segnale identico all'HOT, a cui viene sommato. Il risultato sará che il segnale raddoppia in tensione (ecco perché sugli XLR gira tensione doppia rispetto agli RCA, giá questo irrobustisce la resistenza al rumore) mentre il rumore si somma in controfase annullandosi.
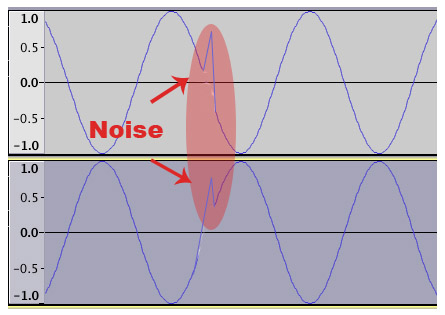
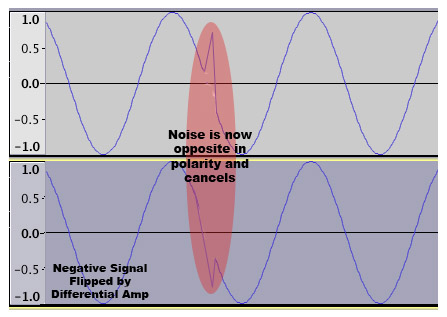 Tale tipologia di trasmissione ha preso subito piede sui palchi di grosse dimensioni, dove un segnale debole come quello di un microfono viaggia per decine di metri prima di arrivare a destinazione, poi introdotto anche nell'hifi come operazione di simpatico marketing. In ambito casalingo difficilmente dovrete far correre cavi lunghi decine di metri e difficilmente passano in ambienti ricchi di dispositivi elettronici ad alta tensione come su un palco, rendendo il sistema quasi inutile. In cuffia si trova un sistema uguale, e molti dicono suoni meglio. Non hanno torto, suona meglio, ma per il fatto che gli ampli progettati per lavorare in bilanciato, sono progettati appunto per lavorare in bilanciato e confrontare l'uscita sbilanciata e bilanciata dello stesso ampli bilanciato, beh é ovvio che suoni meglio quella per cui l'amp é progettato per funzionare, con la single ended l'amp lavora per metá. Confrontate peró uno sbilanciato nativo e uno bilanciato di uguale fascia, come per esempio l'AudioGD NFB 29.38 e l'AudioGD NFB 28.38: nei rispettivi punti di forza, gli ampli suoneranno in maniera molto simile (tolti i casi in cui ovviamente la potenza in piú dell'uscita bilanciata fa comodo). Un altro piccolo vantaggio puó essere dato dal fatto che si hanno masse separate che in alcune cuffie puó dare qualche beneficio in piú.
Tale tipologia di trasmissione ha preso subito piede sui palchi di grosse dimensioni, dove un segnale debole come quello di un microfono viaggia per decine di metri prima di arrivare a destinazione, poi introdotto anche nell'hifi come operazione di simpatico marketing. In ambito casalingo difficilmente dovrete far correre cavi lunghi decine di metri e difficilmente passano in ambienti ricchi di dispositivi elettronici ad alta tensione come su un palco, rendendo il sistema quasi inutile. In cuffia si trova un sistema uguale, e molti dicono suoni meglio. Non hanno torto, suona meglio, ma per il fatto che gli ampli progettati per lavorare in bilanciato, sono progettati appunto per lavorare in bilanciato e confrontare l'uscita sbilanciata e bilanciata dello stesso ampli bilanciato, beh é ovvio che suoni meglio quella per cui l'amp é progettato per funzionare, con la single ended l'amp lavora per metá. Confrontate peró uno sbilanciato nativo e uno bilanciato di uguale fascia, come per esempio l'AudioGD NFB 29.38 e l'AudioGD NFB 28.38: nei rispettivi punti di forza, gli ampli suoneranno in maniera molto simile (tolti i casi in cui ovviamente la potenza in piú dell'uscita bilanciata fa comodo). Un altro piccolo vantaggio puó essere dato dal fatto che si hanno masse separate che in alcune cuffie puó dare qualche beneficio in piú.
PREAMBOLO
Innanzi tutto ci servono due basi matematiche e concettuali, perché senza non si va da nessuna parte e non si riesce a capire una mazza.
Definiamo cos’è un segnale: un segnale è una qualunque grandezza fisica variabile a cui sia associata un’informazione di interesse, rappresentabile con una funzione matematica. Quanti tipi di segnali esistono? Essenzialmente sono 4 e possono essere cosí suddivisi:
- Segnali a tempo continuo e ad ampiezza continua: conosciuto come segnale analogico, dato un intervallo (ad esempio di tensione) in cui operare, questo assume qualsiasi valore in esso, quindi 1.0V ma anche 1.0001V e 1.00000000001V, la stessa cosa avviene nel tempo, è sempre definibile infatti un valore. È rappresentato da una linea continua e variabile.
- Segnali a tempo continuo e ad ampiezza discreta: conosciuto come segnale quantizzato, stavolta è una linea continua ma in ampiezza assume solo valori ben precisi: esiste 1V ma non esiste 0.9V per esempio. Ha un andamento a gradini, ma nel tempo è sempre e comunque definibile un valore (evidentemente dettato dalla scaletta di valori)
- Segnali a tempo discreto e ad ampiezza continua: conosciuto come segnale campionato, stavolta il numero di valori assumibili è illimitato come nel caso analogico, ma il segnale è presente solo a determinati intervalli. Esiste a 0.5 secondi ma non a 0.55 secondi per esempio.
- Segnali a tempo discreto e ad ampiezza discreta: o segnali digitali, esistono solo valori ben determinati sia nel tempo che nell’ampiezza (che per un digitale binario come quelli sull’hard disk sará costituito da soli 0 e 1, quindi saranno solo due livelli)
Impulso unitario: come dice il nome, è un colpo, un qualcosa di istantaneo, di infinitesimamente piccolo nel tempo e alto 1. La sua trasformata vale 1, ovvero è una retta che copre tutte le frequenze. Ebbene si, in un impulso c’è qualsiasi frequenza immaginabile. La proprietá principale è quella del prodotto: prendete un segnale e moltiplicatelo per un impulso, otterrete lo stesso identico segnale spostato nell’istante di applicazione dell’impulso. Viene anche chiamato detto delta di dirac.
Seno e coseno: i due segnali principali della musica, con i quali poi per somma si fanno tutti i timbri possibili. La trasformata di sin2πft è:
Rettangolo: una finestra, un valore che parte da zero, va al massimo e torna a zero. La sua trasformata è
(nota: il simbolo pi greco é il modo matematico di indicare la funzione rettangolo, la variabile T é la durata nel tempo per cui 4π(3t) vuol dire un rettangolo che dura 0.33 secondi centrato nell'origine, alto 4 (per esempio 4 volt se é un segnale elettrico)).
CAMPIONAMENTO
Il suono è come ben sapete un segnale analogico, il segnale in tensione e corrente che esce da un microfono è infatti omogeneo, non presenta scalettature, e segue il normale timbro della voce e di ció che sta captando di altro in quel momento. Dal momento che sugli hard disk il concetto di infinito non esiste, ma al contrario esistono delle dimensioni ben precise, sorge spontanea la domanda: come registro un qualcosa di analogico su un hard disk senza perdere informazioni? Con il campionamento digitale PCM. Molti di voi avranno giá sentito parlare della PCM (da non confondersi con la PWM che non c’entra niente), la PCM è una tecnica che permette la conversione da analogico a digitale e viceversa e sta per Pulse Code Modulation. Immaginiamo ora che dobbiamo registrare una sinusoide ad 1kHz: il processo si svolge in diverse fasi:
la prima fase consiste nel rendere discreto il segnale nel tempo, ovvero di prendere dei punti ad intervalli costanti sulla nostra linea continua in modo da poterli memorizzare. Non possiamo infatti memorizzare gli infiniti punti di un segnale analogico, come detto prima, quindi passeremo prima per un segnale campionato. Viene ottenuto moltiplicando il segnale originario per un treno di impulsi. Gli impulsi avranno quindi altezza pari al nostro segnale (assumeranno il valore del segnale) e nel resto del tempo il segnale sará pari a zero.
Secondo mito da sfatare: “ma i 192kHz rappresentano meglio la banda audio perché la risoluzione è più elevata!” sbagliato: un 44.1kHz rappresenta una frequenza 20kHz esattamente come un 192kHz. Avete mai fatto quei giochi di unire i punti in modo da generare una figura? Mi sapreste disegnare una sinusoide attraverso questi tre punti? E attraverso questi 6?
Siccome il campionamento mediante delta di dirac non è praticabile nella realtá, si utilizzano in realtá dei piccolissimi rettangoli, tale metodo viene chiamato sample and hold (il delta-sigma usato in realtá è ancora un’altra cosa).
Ricordate come i rettangoli in frequenza abbiano un comportamento che ricorda un impulso distorto? É una approssimazione reale del campionamento ideale.
L’altro passaggio è quello di limitare in ampiezza il segnale, ovvero tra gli infiniti valori di tensione che può assumere, stabilirne un determinato numero ed assegnare solo quelli.
Tale procedimento prende il nome di quantizzazione e i valori vengono chiamati livelli di quantizzazione. Ad ogni campione viene associato quindi un livello di quantizzazione espresso in bit, dove 16 bit sono quindi 2^16=65536 livelli e 2^24 sono 16777216 possibili valori. Ovviamente ci sará un errore detto di quantizzazione dato dal fatto che l’ADC non sa se scegliere il valore sopra o quello sotto. L’errore è dato dalla differenza tra il valore massimo e quello minimo possibili (la dinamica del segnale, quindi se il nostro segnale varia tra 0 e 2V sará 2) diviso 2Q, dove Q è il numero di livelli, e il 2 davanti è dovuto al fatto che si fa l’approssimazione per difetto o per eccesso. Più sará grande Q, è minore sará la scalettatura del segnale.
Alla fine abbiamo quindi ottenuto il nostro segnale digitale pronto per essere memorizzato in un file .wav. Terzo mito da sfatare: “più bit abbiamo, migliore sará il suono perché il segnale ha meno errore quindi!” sbagliato: o meglio in teoria avreste ragione, ma la teoria è diversa dalla pratica, infatti i segnali in uscita dai DAC hanno una tensione tipicamente molto bassa per evitare di friggere tutto quello che sta a valle, ricordiamoci che non sono dispositivi di potenza come degli amplificatori. Tale dinamica molto bassa (2V, 4V per i segnali bilanciati – che approfondiremo più avanti) rende giá l’errore di un 16 bit assolutamente microscopico (stiamo parlando quindi di 15 nanovolt) su un 24 bit tale errore è talmente insignificante che viene ampiamente superato dai rumori sulle linee di alimentazione (ecco perché sono importanti sui dac) e dalle precisioni dei resistori nel caso di dac a scala di resistenze. Per farvi un esempio, per stessa ammissione dell’azienda, lo Schiit Yggdrasil, un dac top di gamma da 2600 euro utilizzante quattro dac in cascata di livello militare da 200 euro al chip (dove un delta sigma tradizionale di livello elevato costa 5-6 euro) arriva a 21 bit reali. Un dac da 100 euro ho francamente dei dubbi riesca ad arrivare anche solo a 17 bit reali, tutto il resto è pura fuffa.
Ricapitolando quindi:
limitazione del segnale da codificare al massimo a fc/2 -> campionamento -> quantizzazione -> digitalizzazione.
Il flac è senza dubbio il formato maggiormente conosciuto, esso è come un wav zippato: una volta decompresso on the fly in riproduzione otterrete lo stesso wav con la stessa qualitá dell’originale. Il wav non è superiore al flac, semplicemente il flac è come un archivio rar specializzato per contenere musica, ma il contenuto non viene toccato, infatti è compresso senza perdita.
L’MQA è un formato compresso con perdita di invenzione di Meridian Audio. Anziché offrire una quantizzazione lineare (ovvero con un errore sempre costante) attraverso tecniche di convoluzione e dithering si ottiene un formato con una quantizzazione non lineare, ovvero con un errore sempre crescente mano a mano che si sale in frequenza. Tale logica è suffragata dall’idea che le alte frequenze portano molta meno energia di quelle basse, e quindi un errore in alta frequenza è molto meno percepibile rispetto ad uno in bassa frequenza. Il risultato viene poi compresso con perdita nel formato proprietario, portando le alte frequenze a frapporsi alle basse (mediante dither appunto, come se piegassimo un foglio di carta su sé stesso). I dispositivi che supportano l’MQA via hardware permettono di decodificare il dither applicato e di ottenere nuovamente lo spettro completo, quelli che non lo supportano necessitano di farlo via software e di convertire prima il segnale in PCM.
Il DSD lavora invece su tutt’altra tecnica, la PCM qui non c’entra più una mazza. Il DSD sfrutta la PWM, pulse width modulation: immaginate di poter esprimere una frequenza mediante la modulazione della larghezza di un’onda quadra, che assume quindi solo due valori (ecco perché si dice DSD 1 bit). Avendo un solo bit qui ad aumentare sará la frequenza, fino ai livelli del MHz noti (2.8MHz, 5.6MHz, 11.2MHz) eliminando quindi tutti gli errori dovuti alla quantizzazione, o almeno questa è l’idea. In codifica viene semplicemente fatto passare il segnale in un modulatore PWM, che è fatto con una sorta di comparatore che sceglie se attribuire 0 o 1 in base a dove si trova il segnale. In decodifica e riproduzione, il segnale originato, l’onda quadra, passa in un filtro passa basso che taglia via a frequenze molto inferiori alla portante, per esempio 2.8MHz viene tagliato intorno ai 22kHz. Tale taglio non permette ovviamente di far passare l’onda quadra per intero ma una sua approssimazione “smussata”, la sinusoide di partenza. Di preciso, si nota che tagliando via a frequenze più basse il valore assunto dal segnale corrisponde all’area del rettangolo dell’onda, per cui un’onda quadra molto stretta genera un segnale vicino allo 0 mentre un’onda quadra molto larga un segnale vicino al massimo (2V tipicamente), per approssimazione. È abbastanza intuitivo. È LO STESSO IDENTICO sistema di funzionamento di un alimentatore switching come quelli per PC, solo che li la frequenza è fissa e tarata per generare una tensione di 12V. Facendo variare la frequenza come nel DSD si produce un amplificatore in classe D, anch’esso lavora sul principio della PWM, dove i transistor sono solo utilizzati in commutazione (0 e 1) e mai in zona lineare.
Quali sono i vantaggi reali? Beh come funziona la modulazione delta-sigma? Intanto cosa significa delta-sigma? Delta rappresenta un impulso (la delta di dirac per l'appunto), sigma significa somma di impulsi (il simbolo della sommatoria matematica). Notate somiglianze? Eh giá sono la stessa cosa (quasi - in realtá é leggermente diversa ma comunque simile come concetto): delta-sigma e modulazione a larghezza di impulsi (pulse width modulation) sono quasi la stessa cosa, infatti i dac e gli adc nativamente funzionano proprio in questo modo, quindi per registrare in DSD basta prendere l'out grezzo dell'adc e senza passaggi in codificatori PCM ma solo con poche manipolazioni, inciderlo su disco, il SACD. Per lavorare in PCM infatti un dac o un adc ha bisogno di passaggi intermedi che permettono la decodifica in delta sigma mediante un lavoro in parallelo non molto distante da una sorta di multithreading (qualcuno ricorda il multibit di schiit... quello lavora nativamente in PCM, guarda caso non accetta stream DSD... guarda caso sui vecchi prodotti audio, ho giusto qui sotto mano un lettore cd kenwood dell'anteguerra, quando la tecnologia era agli albori si chiamavano dac 1 bit e non ancora delta sigma...). Il DSD é quindi meglio del PCM? Ni, o meglio, sebbene elimini gli errori dati dalla quantizzazione, il campionamento viene condotto ad altissima frequenza e giá questo puó introdurre errori che lo rendono piú sensibile al jitter (problemi derivanti dalla sincronizzazione con i clock) in piú il comparatore introduce errori dovuti al fatto che puó scegliere tra soli due valori e tale errore consiste solo in uno spostamento di responsabilitá rispetto ai classici errori di quantizzazione per la PCM.
L'MP3 é nato intorno agli anni '90 e si proponeva di ridurre il grande volume di dati occupato da un file wav PCM in livelli molto piú accettabili per dei dispositivi portatili. siccome giá 44.1kHz era la frequenza minima imposta per campionare senza perdere dati nella banda audio, si é inizialmente scelto di diminuire i campioni a 8 bit, dimezzando la mole di dati (44.1kHz x 16 bit x 2 originava un flusso da 1411kbit/s, con 8 bit si passava a 705.5kbit/s) ottenendo peró un suono parecchio peggiore, a livelli veramente pessimi. Si é quindi pensato di passare a considerare il segnale in frequenza, lo spettro. Dividendo tale segnale in 32 sottobande con dei filtri e campionando tale spettro come se fosse un segnale nel tempo si possono utilizzare largamente meno bit, permettendo una occupazione notevolmente minore. Accanto all'MP3 si sviluppava anche tutta una ricerca su modelli percettivi del suono, per fare in modo di tagliar via le frequenze poco importanti (esempio oltre i 18kHz e sotto i 20Hz) in modo da rendere piú fitte le 32 bande e concentrare la precisione nelle frequenze di maggior interesse, codificati con codificatori come LAME, si ottengono i risultati che oggi conosciamo con bitrate massimi di 320kbit/s. Ulteriori miglioramenti in termini di compressione sono stati introdotti con il codec MP3 joint stereo, dove si osservava che i segnali destro e sinistro presentano essenzialmente poche variazioni l'uno con l'altro, per cui si registrava in mono e su una traccia a parte si registravano le sole variazioni da un canale all'altro, migliorando sensibilmente l'occupazione in termini di dati utilizzati. É stato introdotto non molto tempo fa il formato VBR, ovvero variable bit rate, che prevede l'associazione a ciascuno dei 32 frame di spettro (chiamati chunks) di un numero di bit differenti a seconda sia della dinamica del segnale, sia considerando il fatto che la gamma bassa essendo meno complessa necessita di meno bit rispetto a quella alta, in una maniera analoga alla quantizzazione non lineare.
LA STREGONERIA DEI SEGNALI BILANCIATI
Visto che su internet ormai si legge di tutto, non é raro leggere anche di gente che preferisce la connessione bilanciata perché "é piú meglio" - credo ci sia anche una setta del segnale bilanciato, come esistono quelle per i cavi di alimentazione in tondini d'argento, probabilmente l'inizializzazione é un qualcosa di strano dove gente viene legata tramite cavi XLR e poi succedono cose che non ci é dato sapere. Per capire come questa storia del bilanciato come segnale preferibile sia una bufala, bisogna capire prima come funziona un segnale bilanciato e qual é la differenza con uno sbilanciato. Nel segnale sbilanciato, abbiamo un riferimento a 0V che viene mantenuto costante ed é il negativo, la parte esterna di un RCA, mentre il vero segnale viaggia tutto sul positivo, il pin centrale. Questo sistema rende la trasmissione vulnerabile ad eventuali rumori, vedi figura.
Ultima modifica da un moderatore: