Giuseppe1985
Utente Attivo
- Messaggi
- 185
- Reazioni
- 0
Volevo propormi di parlare sulla nascita ormai nn troppo lontana delle nuove piattaforme amd:
SSE a 128bit
Una delle principali caratteristiche architetturali delle cpu Intel Core 2 è data dalla gestione delle istruzioni SSE a 128bit; questa caratteristica permette alle soluzioni Intel di essere sensibilmente più veloci delle soluzioni AMD64.
AMD è corsa ai ripari con il nuovo core K10, inserendo anche in questa architettura il supporto SSE a 128bit e raddoppiando, di fatto, tutti gli elementi ad esso collegati. Se con i processori della famiglia K8 AMD può eseguire due operazioni SSE per ciclo di clock, con execution unit ampie 64bit, con K10 AMD può eseguire sempre due operazioni SSE per ciclo di clock, ma con execution unit da 128bit. La conseguenza diretta è che in presenza di un'istruzione SSE a 128bit di ampiezza una execution unit di K10 necessita di un solo ciclo di clock per completare l'operazione, mentre K8 deve dividere l'istruzione come se fosse composta da due distinte operazioni da 64bit ciascuna.
L'aver introdotto execution unit SSE a 128bit ha spinto AMD ha raddoppiare sia la bandwidth delle instruction fetch, passata da 16bit a 32bit per ciclo di clock, che la bandwidth della data cache, raddoppiata da 2x64bit a 2x128bit loads per ciclo di clock. Per poter fornire i dati alle execution unit in tempo, senza che queste debbano attendere sprecando cicli di clock inutilmente, AMD ha raddoppiato l'ampiezza della bandwidth che collega la cache L2 e il north bridge tra di loro, passando dai 64bit dell'architettura K8 ai 128bit di quella K10.
Non solo: è stata raddoppiata anche la bandwidth tra la cache L1 per i dati e i registri SSE, passando da 2 load a 64bit per ciclo di clock a 2 load a 128bit per ciclo di clock; questo permette di trasferire dalla memoria 128bit per ogni ciclo di clock, saturando completamente e sfruttando appieno tutti i bus raddoppiati rispetto a K8 sino a giungere alle execution unit. Ovviamente anche la bandwidth tra cache L2 e L1 è stata raddoppiata, così da non creare un collo di bottiglia al trasferimento dei dati verso le execution unit.
Lo scheduler per le operazioni in virgola mobile è stato raddoppiato: è sempre del tipo a 36 entry come quello utilizzato nei processori K8, ma con ampiezza passata da 64bit a 128bit. Nelle architetture Core di Intel lo scheduler è a 32 entry a 128bit, ma condiviso tra operazioni di tipo floating point e quelle su numeri interi.
AMD, quindi, con K10 ha operato da un lato per raddoppiare la potenza elaborativa delle execution unit SSE, portandole a 128bit, e dall'altro a fare in modo che i dati possano passare dalla memoria alle cache e da queste alle execution unit così che i 128bit di ampiezza siano sempre completamente sfruttati, evitando che sussistano dei colli di bottiglia.
Caratteristiche Tecniche Generali dell'amd Phenom(k10):
- nuove estensioni SSE4;
- supporto SSE dual 128bit, contro quello a 64bit delle attuali versioni di processore Athlon 64 e Opteron
- scheduler in virgola mobile a 36 vie, con ampiezza passata da 64 a 128 bit;
- raddoppio della bandwidth delle instruction fetch, passando da 16 a 32 bytes per ciclo di clock;
- nuova generazione di bus HyperTransport, revision 3.0, inizialmente solo per i processori desktop e in seguito anche sulle soluzioni server;
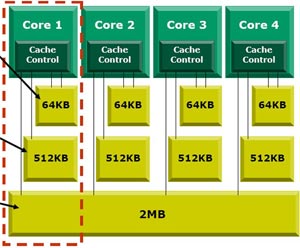
- raddoppio del bus tra le cache L1 e L2, passato da 128bit a 256bit (2 bus indipendenti da 128bit);
- prefetcher modificati per fornire dati direttamente alla cache L1;
- aggiunta di un prefetcher DRAM integrato nel memory controller;
- memory controller ottimizzato, specificamente sviluppato per sfruttare la presenza di 4 core;
- tecnologia di virtualizzazione migliorata;
- gestione del risparmio energetico più avanzata che in K8.
- Passaggio di molte istruzioni, anche di tipo intero, da Vector path a directPath: quindi superiori prestazioni sia in decodifica (maggiori istruzioni decodificabili) che in esecuzione (meno macro-ops da eseguire). Molte SSE, sopratutto quelle a 128 bit, sono state declassate, ma anche le CALL e le RET (usate frequentissimamente) e altre istruzioni intere.
- Nuova branch prediction unit per i salti indiretti, espansione delle altre branch prediction unit, return stack espanso e Sideband stack optimizer (libera unità intere dall'esecuzione di operazioni stack: molto utile).
- Controller RAM e cache L3 sullo stesso power plane e con lo stesso PLL. Da impostazioni di default dovrebbero andare ad una frequenza superiore di 200-400 MHz a quella massima del core e con un leggero over volt (solo su socket AM2+). Avendo frequenza e tensione separata, il controller RAM non sarà più un collo di bottiglia durante overclock spinti, potendone abbassare il moltiplicatore e/o modificare la tensione di alimentazione.
- Super forwarding per alcune operazioni floating point e load da memoria.
- Eliminazione delle limitazione di esecuzione di alcune istruzioni floating point su specifiche pipeline: nel k8 alcune istruzioni potevano essere eseguite solo su una pipeline specifica (FADD, FMUL o FSTOR), ora alcune istruzioni sono state modificate in modo da poter usare due o qualsiasi pipeline.
- Nuovi TLB per pagine da 1GB (utili sopratutto per la virtualizzazione).
Entriamo del dettaglio:
SSE a 128bit
Una delle principali caratteristiche architetturali delle cpu Intel Core 2 è data dalla gestione delle istruzioni SSE a 128bit; questa caratteristica permette alle soluzioni Intel di essere sensibilmente più veloci delle soluzioni AMD64.
AMD è corsa ai ripari con il nuovo core K10, inserendo anche in questa architettura il supporto SSE a 128bit e raddoppiando, di fatto, tutti gli elementi ad esso collegati. Se con i processori della famiglia K8 AMD può eseguire due operazioni SSE per ciclo di clock, con execution unit ampie 64bit, con K10 AMD può eseguire sempre due operazioni SSE per ciclo di clock, ma con execution unit da 128bit. La conseguenza diretta è che in presenza di un'istruzione SSE a 128bit di ampiezza una execution unit di K10 necessita di un solo ciclo di clock per completare l'operazione, mentre K8 deve dividere l'istruzione come se fosse composta da due distinte operazioni da 64bit ciascuna.
L'aver introdotto execution unit SSE a 128bit ha spinto AMD ha raddoppiare sia la bandwidth delle instruction fetch, passata da 16bit a 32bit per ciclo di clock, che la bandwidth della data cache, raddoppiata da 2x64bit a 2x128bit loads per ciclo di clock. Per poter fornire i dati alle execution unit in tempo, senza che queste debbano attendere sprecando cicli di clock inutilmente, AMD ha raddoppiato l'ampiezza della bandwidth che collega la cache L2 e il north bridge tra di loro, passando dai 64bit dell'architettura K8 ai 128bit di quella K10.
Non solo: è stata raddoppiata anche la bandwidth tra la cache L1 per i dati e i registri SSE, passando da 2 load a 64bit per ciclo di clock a 2 load a 128bit per ciclo di clock; questo permette di trasferire dalla memoria 128bit per ogni ciclo di clock, saturando completamente e sfruttando appieno tutti i bus raddoppiati rispetto a K8 sino a giungere alle execution unit. Ovviamente anche la bandwidth tra cache L2 e L1 è stata raddoppiata, così da non creare un collo di bottiglia al trasferimento dei dati verso le execution unit.
Lo scheduler per le operazioni in virgola mobile è stato raddoppiato: è sempre del tipo a 36 entry come quello utilizzato nei processori K8, ma con ampiezza passata da 64bit a 128bit. Nelle architetture Core di Intel lo scheduler è a 32 entry a 128bit, ma condiviso tra operazioni di tipo floating point e quelle su numeri interi.
AMD, quindi, con K10 ha operato da un lato per raddoppiare la potenza elaborativa delle execution unit SSE, portandole a 128bit, e dall'altro a fare in modo che i dati possano passare dalla memoria alle cache e da queste alle execution unit così che i 128bit di ampiezza siano sempre completamente sfruttati, evitando che sussistano dei colli di bottiglia.