ilfe98
Utente Èlite
- Messaggi
- 3,083
- Reazioni
- 1,317
- Punteggio
- 134
Salve a tutti,
Oggi vorrei fare una piccola introduzione su un argomento che è ormai onnipresente nella nostra vita quotidiana. Purtroppo non è assolutamente facile per me cercare di esporre un argomento così complesso testualmente ed evitare il più possibile i richiami matematici, ma cercherò di fare del mio meglio. Perciò siate clementi.
Le intelligenze artificiali sono campo di ricerca incredibilmente attivo nell'ambito informatico. Chiariamo che non parliamo di macchine senzienti in grado di pensare, ma rendendo tutto molto semplice sono degli algoritmi che cercano di trarre il positivo dall'evoluzione umana. Al contrario di ciò che si pensa non sono un concetto nato negli ultimi 10 anni, ma sono molto più datati. Il trend di ricerca attuale nasce dal 2006, ma il primo percettrone è stato (fatemi passare il termine per il momento) trainato nel ventennio 1940-60 ed è stato affinato fino all'attuale formulazione che vi ho citato poco fa. Ciò che ha reso attuale l'idea è che grazie al progresso tecnologico abbiamo a disposizione set di dati più grandi, maggior potenza computazionale, fase di train su gpu e scalabilità. Le performance degli algoritmi di Deep Learning crescono con l'aumentare dei dati il che segue una delle motivazioni per le quali sono ormai di moda.È importante definire correttamente la rappresentazione dei dati che vogliamo analizzare, in quanto essi sono un ulteriore motivazione di pessime performance negli algoritmi di machine learning, questa modellazione discreta dei dati viene risolta automaticamente dagli algoritmi di deep learning.
Come ho detto, gli algoritmi di deep learning prendono spunto dalla biologia umana, ma in che modo?
Oggi vorrei fare una piccola introduzione su un argomento che è ormai onnipresente nella nostra vita quotidiana. Purtroppo non è assolutamente facile per me cercare di esporre un argomento così complesso testualmente ed evitare il più possibile i richiami matematici, ma cercherò di fare del mio meglio. Perciò siate clementi.
Le intelligenze artificiali sono campo di ricerca incredibilmente attivo nell'ambito informatico. Chiariamo che non parliamo di macchine senzienti in grado di pensare, ma rendendo tutto molto semplice sono degli algoritmi che cercano di trarre il positivo dall'evoluzione umana. Al contrario di ciò che si pensa non sono un concetto nato negli ultimi 10 anni, ma sono molto più datati. Il trend di ricerca attuale nasce dal 2006, ma il primo percettrone è stato (fatemi passare il termine per il momento) trainato nel ventennio 1940-60 ed è stato affinato fino all'attuale formulazione che vi ho citato poco fa. Ciò che ha reso attuale l'idea è che grazie al progresso tecnologico abbiamo a disposizione set di dati più grandi, maggior potenza computazionale, fase di train su gpu e scalabilità. Le performance degli algoritmi di Deep Learning crescono con l'aumentare dei dati il che segue una delle motivazioni per le quali sono ormai di moda.È importante definire correttamente la rappresentazione dei dati che vogliamo analizzare, in quanto essi sono un ulteriore motivazione di pessime performance negli algoritmi di machine learning, questa modellazione discreta dei dati viene risolta automaticamente dagli algoritmi di deep learning.
Come ho detto, gli algoritmi di deep learning prendono spunto dalla biologia umana, ma in che modo?
PERCETTRONE
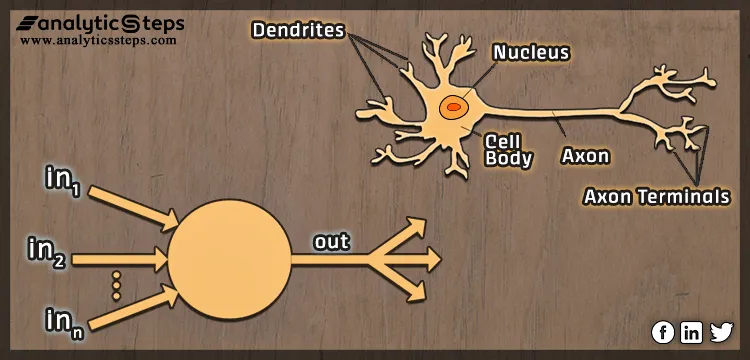
Purtroppo sono necessarie alcuni nozioni matematiche al fine di comprendere il funzionamento delle reti. Cerco di evitare il possibile pertanto se ci fossero alcune imprecisioni sono da considerare esemplificative.
L'immagine sopracitata rappresenta in che modo la cella elementare delle reti neurali trae benefici dalla biologia.
Da un punto di vista formale si ha una serie di ingressi rappresentati con In1,In2...Inn che provengono dall'input che non è altro un vettore k-dimensionale, dove k rappresenta le coordinate necessarie per rappresentare il punto nel suo spazio.
Ad esempio se giacessimo su un piano, le coordinate necessarie sarebbero 2 le solite x e y, ma è molto frequente avere degli spazi detti n-dimensionali dove il numero di coordinate dipende da n.
Gli input confluiscono nella cella in basso a sinistra chiamata percettrone, esso attraverso la combinazione lineare di sinapsi e input produrra un output.
Tornando al nostro percettrone, il vettore di features non è l'unico possibile input della rete, ma dato che allerta spoiler, le reti neurali sono composte da una molteplicità di questi percettroni, l'input può essere anche l'output del layer precedente.
L'immagine sopracitata rappresenta in che modo la cella elementare delle reti neurali trae benefici dalla biologia.
Da un punto di vista formale si ha una serie di ingressi rappresentati con In1,In2...Inn che provengono dall'input che non è altro un vettore k-dimensionale, dove k rappresenta le coordinate necessarie per rappresentare il punto nel suo spazio.
Ad esempio se giacessimo su un piano, le coordinate necessarie sarebbero 2 le solite x e y, ma è molto frequente avere degli spazi detti n-dimensionali dove il numero di coordinate dipende da n.
Gli input confluiscono nella cella in basso a sinistra chiamata percettrone, esso attraverso la combinazione lineare di sinapsi e input produrra un output.
Tornando al nostro percettrone, il vettore di features non è l'unico possibile input della rete, ma dato che allerta spoiler, le reti neurali sono composte da una molteplicità di questi percettroni, l'input può essere anche l'output del layer precedente.
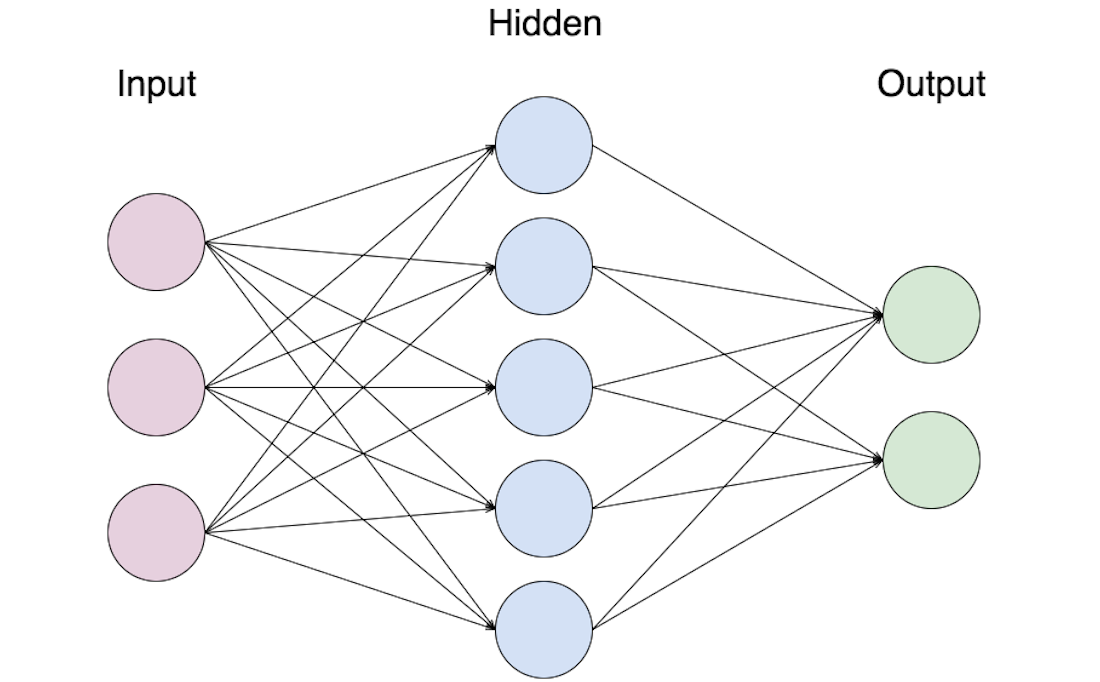
I layer sono una "pila" di percettroni che elaborano simultaneamente una feature. La sinapsi è ciò che modella la natura dei segnali elettrici, esse saranno i pesi della nostra rete neurale.
Prendo ogni singolo ingresso, lo moltiplico per il peso e ne faccio la somma (aggiungendoci un vettore di bias che eviterò di trattare per cercare di rendere tutto più smooth). Nel nostro cervello a questo punto dovremmo cominciare ad elaborare qualche pensiero, ovvero avvere dei neuroni accesi... Parallelamente nella nostra rete la sommatoria menzionata prima viene passata per una funzione detta: funzione di attivazione.
Questa funzione consiste nel sogliare la nostra combinazione lineare e darne un valore scalare in output. Senza entrare in tecnicismi, la nostra funzione di attivazione sarà la ReLU, che per "sommatorie" positive restituisce esattamente quel valore.
La foto precedente, mostra un'architettura molto semplice di rete neurale densa, è quella che oggi modelleremo assieme.
Il primo layer in rosa, riceve il nostro input, lo elabora e lo fornisce al nostro hidden layer, che a sua volta lo fornisce all'output. La quasi totalità delle volte ci sono molti hidden layer.
L'ultimo strato, di output avrà un numero di neuroni determinato: Ha tanti neuroni quanto sono le classi che noi vogliamo rappresentare. Ad esempio se avessimo delle cifre e volessimo classificare la singola cifra, dovremmo avere esattamente 10 neuroni nel layer di output(0-9).
La fase di addestramento della nostra rete neurale è un processo iterativo, significa che posso far scorrere i miei dati da sinistra a destra per tot volte prima di fermarmi, quando esattamente mi fermo?
A livello logico mi fermo quando la mia rete riesce a riconoscere le cifre correttamente.
Nelle dense nn questo meccanismo viene implementato da una funzione chiamata loss e da un algoritmo chiamato di backpropagation.
Qualche riga fa se ricordate vi ho menzionato i pesi della rete, essi sono esattamente gli elementi che devo modificare nella mia rete affinche apprenda il mio task, ovvero classificare le cifre.
Per ogni input alla fine della rete, ovvero sull'output la mia loss. La loss indica quanto io mi stia sbagliando. Nel caso delle dense nn può farlo in quanto il mio vettore di feature chiamato X ha associato un altro vettore detto di label chiamato Y, in questo vettore ho un 1 nella cella che corrisponde alla classe del dato, 0 nelle altre.
Pertanto utilizzando una loss( che nel nostro caso sarà la cross-entropy) posso fare in modo, cambiando i pesi che il mio dato dato in input venga classificato correttamente dalla nostra rete.
Il funzionamento descritto, è davvero sommario, ci sarebbero una miriade di informazioni da aggiungere, per questo motivo i coraggiosi che leggeranno il thread potranno chiedermi di entrare sempre più nel dettaglio facendomi delle domande mirate. In questo primo messaggio, il mio goal è svelarvi la magia dietro il deep learning.
Passiamo al lato pratico. In questa fase dato che sono certo non abbiate voglia di installare tutte le dipendenze mi avvalgo di una piattaforma di coding online, chiamata Google Colab.
Su questa piattaforma vi scriverò il codice commentato riportato qui sotto che a partire da un dataset( ovvero un insieme di elementi k-dimensionali e rispettive label y) chiamato MNIST possiamo classificare delle immagini che riportano cifre scritte a mano.
MULTI-LAYER PERCEPTRON
In questo codice faremo uso di un framework per il machine learning chiamato pytorch, esso è gia installato nelle VM di google colab.
Recatevi su colab create un blocco note, e nella prima cella inserite questo e cliccate su play:
Python:
import torch
torch.cuda.is_available()Da inserisci create una nuova cella e incollate:
In questa porzione di codice stabiliamo su quanti per volta dobbiamo trainare la nostra rete, la fase di aggiornamento della rete considererà 128 elementi per volta, successivamente effettuiamo una conversione in tensori e normalizziamo i dati.
Python:
import numpy as np
from matplotlib import pyplot as plt
from torchvision import transforms
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
from torchvision.datasets import MNIST
BATCH_SIZE = 128
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
Python:
mnist_train = MNIST('data',train=True,transform=transform, download=True)
mnist_test = MNIST('data',train=False,transform=transform, download=True)
dl_train = DataLoader(dataset=mnist_train, batch_size=BATCH_SIZE,
num_workers=0, drop_last=True, shuffle=True)
dl_test = DataLoader(dataset=mnist_test, batch_size=BATCH_SIZE,
num_workers=0, drop_last=False, shuffle=False)
Python:
import torch
num_epochs = 20
num_fin = 784
num_classes = 10
num_hidden = 128
learning_rate = 0.01
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
Python:
import torch
import torch.nn as nn
from torch.optim import SGD
class MLP(nn.Module):
def __init__(self, num_fin: int, num_hidden: int, num_classes: int):
super(MLP, self).__init__()
self.net = nn.Sequential(
nn.Linear(num_fin, num_hidden),
nn.ReLU(),
nn.Linear(num_hidden, num_classes)
)
def forward(self, x: torch.Tensor):
return self.net(torch.flatten(x, 1))
def eval_acc(mlp: nn.Module, data_loader: torch.utils.data.DataLoader,
device: torch.device):
correct = 0
total = 0
with torch.no_grad():
for x, y in data_loader:
x, y = x.to(device), y.to(device)
y_pred = model(x)
y_pred_discr = torch.argmax(y_pred, dim=1)
acc = torch.sum((y_pred_discr == y).float())
correct += acc
total += y_pred.size(0)
return correct/total
Python:
model = MLP(num_fin, num_hidden, num_classes).to(device)
loss_fun = nn.CrossEntropyLoss().to(device)
opt = SGD(model.parameters(), learning_rate)
try:
for i in range(num_epochs):
print(f"Epoch {i} accuracy_train.: {eval_acc(model, dl_train, device):.3f} "
f"test.: {eval_acc(model, dl_test, device):.3f}")
for x, y in dl_train:
x, y = x.to(device), y.to(device)
opt.zero_grad()
pred = model(x)
loss = loss_fun(pred, y)
loss.backward()
opt.step()
except KeyboardInterrupt:
passDifatti i test effettuati confermano le predizioni corrette.
