Continuo quì visto che comunque l'argomento è il Directstorage e magari può interessare aggiungere tasselli sul funzionamento lato storage.
Parto dalle mie considerazioni:
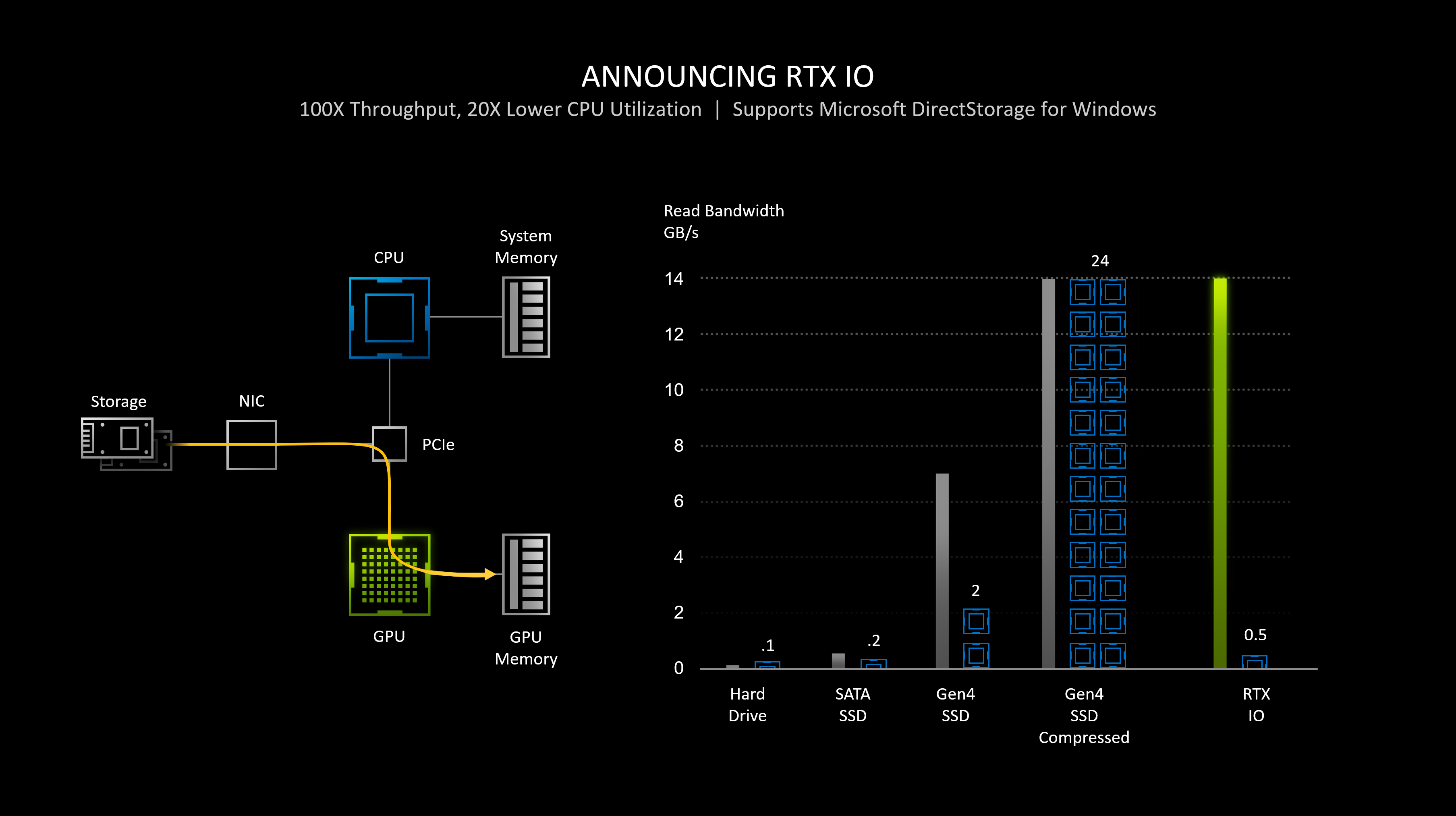
Ecco pensavo che, per usare appieno un ssd nvme si dovesse sfruttare la grandezza dei dati (in forma di blocchi aggregati) e la velocità sequenziale, invece da ciò che viene scritto: "DirectStorage per Windows sostituisce l'API Win32 FileIO con una nuova API progettata per un numero molto elevato di richieste di file di piccole dimensioni. Ciò consente ai giochi moderni di estrarre le proprie risorse dallo storage molto più rapidamente e di saturare l'elevata larghezza di banda degli SSD NVMe.
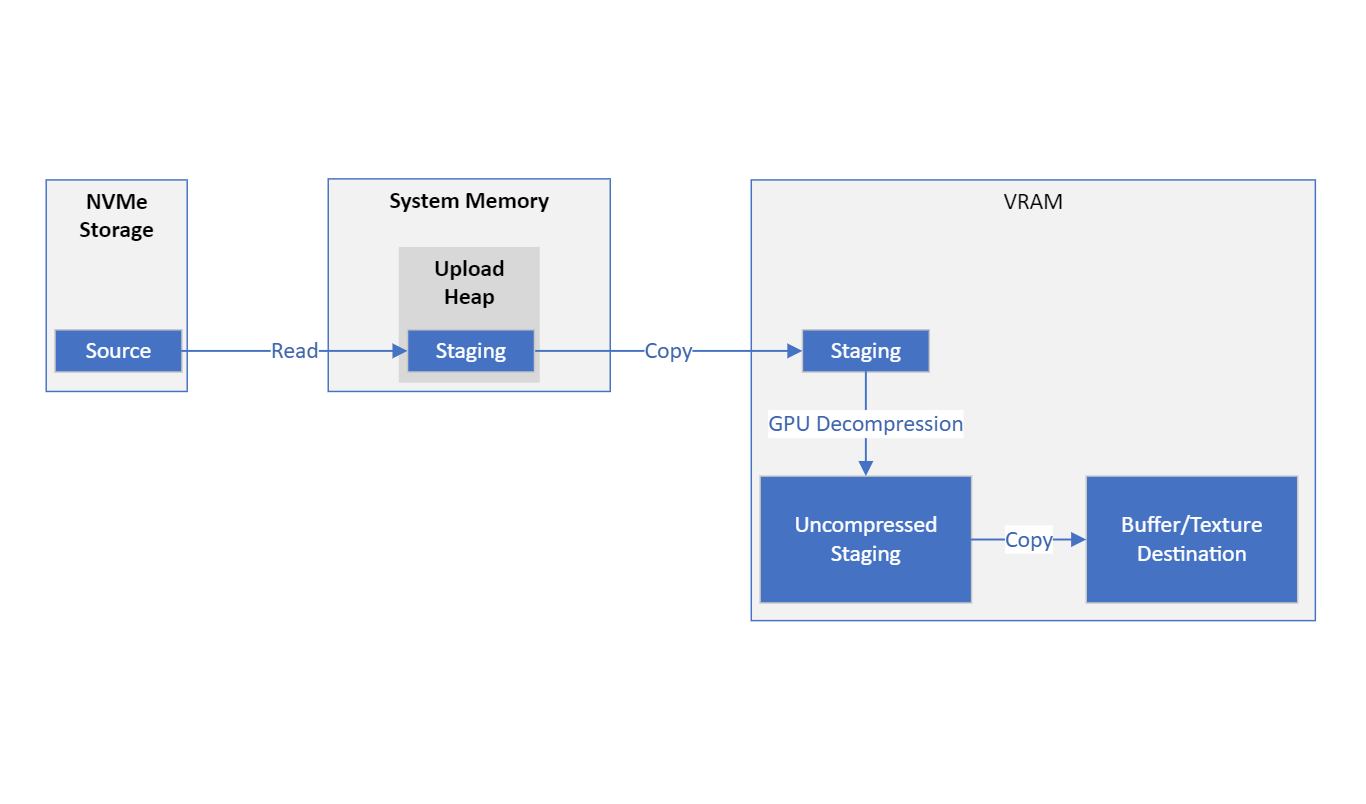
La curiosità quindi è diventata capire la dimensione dei blocchi trasferiti su richiesta della nuova API da ssd a gpu finendo sulla ram di sistema come è stato appurato.
Da quà
The DirectStorage team is pleased to share that GPU decompression with DirectStorage 1.1 is available now. This new version of DirectStorage contains everything a developer needs to get started with GPU decompression. For more information on this feature and how it benefits gamers, check out our...

devblogs.microsoft.com
si capisce che i blocchi sono da 64KiB.
Una dimensione che apparentemente è piccola, vicinissima ai 4KiB dei blocchi assunti come caratteristici del transfert rate di un sistema operativo e che anche i nuovissimi pcie 5.0 non riescono a implementare
https://www.techpowerup.com/304463/first-consumer-pcie-5-0-nvme-ssd-gets-tested-makes-a-lot-of-noise
La realtà è diversa, non ho considerato tutto

.
Prendendo ad esempio Crystaldiskmark appare evidente che basta un file da 1MiB per far considerare pienamente il test come trasferimento "sequenziale".
Altra cosa è la Coda di comandi che questi ssd (nvme in generale ma sopratutto i gen 4) gestiscono, e che è un discorso completamente avulso agli ssd sata che hanno un accodamento max di 32.
Infine il parallelismo cioè la capacità di far fronte a più comandi diversi (anche lettura e scrittura insieme). Quindi un ssd nvme può gestire molti thread, specie in lettura, ma essendo la richiesta di lettura venire prevalentemente dalla gpu, sarà a thread unico.
Ho fatto una prova proprio con Crystaldiskmark mettendo alla seconda e terza riga come file di test proprio un 64KiB
Beh! Un risultato decisamente convincente: in pratica un file da 64KiB con una coda doppia di quella comunemente gestibile da un ssd sata,
può essere quasi paragonata ad un lettura sequenziale.
E lo è anche per il sata nonostante aver impostato una coda di comandi superiore a quella che gestisce...
EDIT.

altre riflessioni; ho aggiustato.